
22. 05. 2026
AI, NetEye, Unified Monitoring

02. 08. 2017
Susanne Greiner
NetEye, Real User Experience Monitoring
Next Level Performance Monitoring – Part II: Welche Rolle spielen Machine Learning und Anomalie Detection?
Immer öfter hören wir im Zusammenhang mit Performance Monitoring auch die Begriffe Machine Learning und Anomaly Detection. Aber was genau bedeuten sie und warum erfreuen sie sich immer größerer Beliebtheit?
Von Statistik zu Machine Learning
Bereits mehrfach wurde versucht die genauen Unterschiede zwischen Machine Learning und Statistik aufzuzeigen, in der Tat ist es gar nicht so einfach eine klare Trennlinie zwischen den beiden Begriffen zu ziehen.
Experten sagen:
- “Es gibt keinen Unterschied zwischen Machine Learning und Statistik” (in Hinblick auf Mathematik, Bücher, Lehre usw.)
- “Machine Learning ist etwas ganz anderes als Statistik” (und allein Machine Learning wird in Zukunft bestehen)
- “Statistik ist das einzig Wahre” (Machine Learning ist nur eine andere Bezeichnung für einen Teilbereich der Statistik, welcher von Personen verwendet wird, die das wahre Konzept hinter dem, was sie tun, nicht verstanden haben.)
Interessierten Lesern empfehle ich die Lektüre von:
Breiman – Statistical Modeling: The Two Cultures und Statistics vs. Machine Learning, fight!
Kurz gesagt, werden wir diese Frage wohl nicht so schnell beantworten können. Trotzdem ist es für Monitoringbeauftragte interessant zu wissen, dass sich die Machine Learning und Statistik Communities aktuell in verschiedene Richtungen bewegen. Für sie wird es in Zukunft wichtig sein, Methoden beider Felder anzuwenden. Die Statistik-Seite konzentriert sich auf das Konzept der Inferenz (sie wollen den Prozess herausfinden, der die Daten generiert hat). Die Machine Learning Community hingegen, beschäftigt sich vorwiegend mit der Prognose von erwarteten, zukünftigen Daten. Es liegt also auf der Hand, dass die beiden Interessensgebiete nicht ganz unabhängig voneinander existieren können. Kenntnisse im Bereich des generierenden Modells können für die Entwicklung eines besseren Prognose- oder Anomaly Detection Algorithmus angewendet werden.
Anomaly Detection und Standard Alerting
Vor einiger Zeit schien Baselining DIE Lösung für die Definition aussagekräftiger Alerts zu sein. Heutzutage, in der Zeit von heterogenem Netzwerk Traffic und Internet of Things, bedarf es jedoch neuer Strategien. Und genau hier kommt Anomaly Detection ins Spiel. Aber was genau ist eine Anomalie? Ein Datenpunkt der aus irgendeinem Grund nicht dem Standard entspricht. Allerdings gibt es verschiedene Typen von Anomalien:
- Punktanomalie: Ein einziger Datenpunkt unterscheidet sich vom Rest. Ein Beispiel könnte in Prozessor sein, der sich immer in einem gewissen Bereich bewegt und dann plötzlich eine Spitze außerhalb dieses Bereichs aufweist.

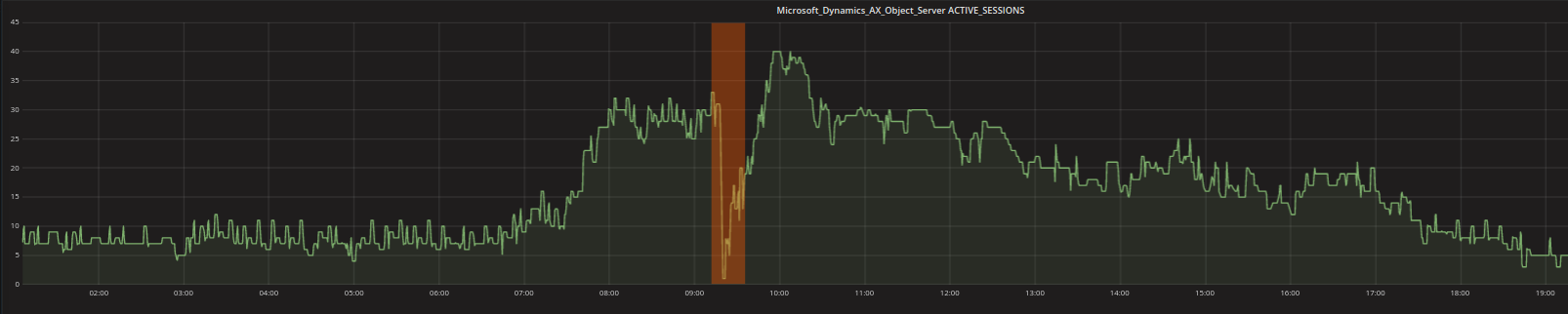
- Kontextanomaly: Ein oder mehrere Datenpunkte können als Anomalie deklariert werden, wenn sie in Zusammenhang mit den restlichen Daten eigenartig erscheinen. Zum Beispiel können Werte die in der Nacht typisch sind, während der normalen Arbeitszeit abnormal sein. Die niedrigen Werte im unten stehenden Graph sind also nicht untypisch weil sie niedrig sind (es gibt viele niedrige Werte), sondern weil sie während des Tages niedrig sind, wenn eigentlich höhere Werte erwartet werden.
- Kollektivanomaly: Die Kombination mehrerer Gegebenheiten lässt vermuten, dass eine Anomalie vorliegt (mehrere Daten oder Metriken zusammen, nicht einzelne Metrikwerte). Häufig handelt es sich dabei um Events in einer unerwarteten Reihenfolge oder unerwartete Kombinationen von Werten. z.B. eine Spitze in der Processor Time kann plausibel sein, so lange vom Prozessor bekannte und gewollte Transaktionen ausgeführt werden. Kommt es hingegen zu einem Prozessorpeak in Kombination mit anderen Metriken, die auf einen Lehrlauf hinweisen sollte unbedingt Zeit in die genauere Untersuchung dieser Situation investiert werden.
Was bedeutet das nun konkret? Einfach ausgedrückt bedeutet das, dass es Situationen gibt, in denen Standardmethoden nicht in der Lage sind, einen Alarm auszulösen, weil es für das Erkennen einer vorliegenden Anomalie ausgereiftere Techniken als reines Baselining bedarf. Damit möchte ich nicht sagen, dass solche fortgeschrittene Techniken das Baselining komplett ersetzen, ich erachte sie jedoch als wirksame Ergänzung zu den Standardverfahren.
Next Level Performance Monitoring
Lassen Sie uns nun genauer betrachten wie Anomaly Detection das Next Level Performance Monitoring bereichert. Was würde eine Fachkraft tun, um zu erkennen warum ein System Performanceeinbußen (oder andere Probleme) vorweist?
- Kontrollieren ob tatsächlich ein Problem vorliegt.
- Versuchen zu erkennen woher das Problem kommt.
- Das Problem weiter analysieren.
- Das Problem beheben und versuchen proaktiv ähnliche Probleme vermeiden.
In der Praxis könnte das für Sie folgendes bedeuten:
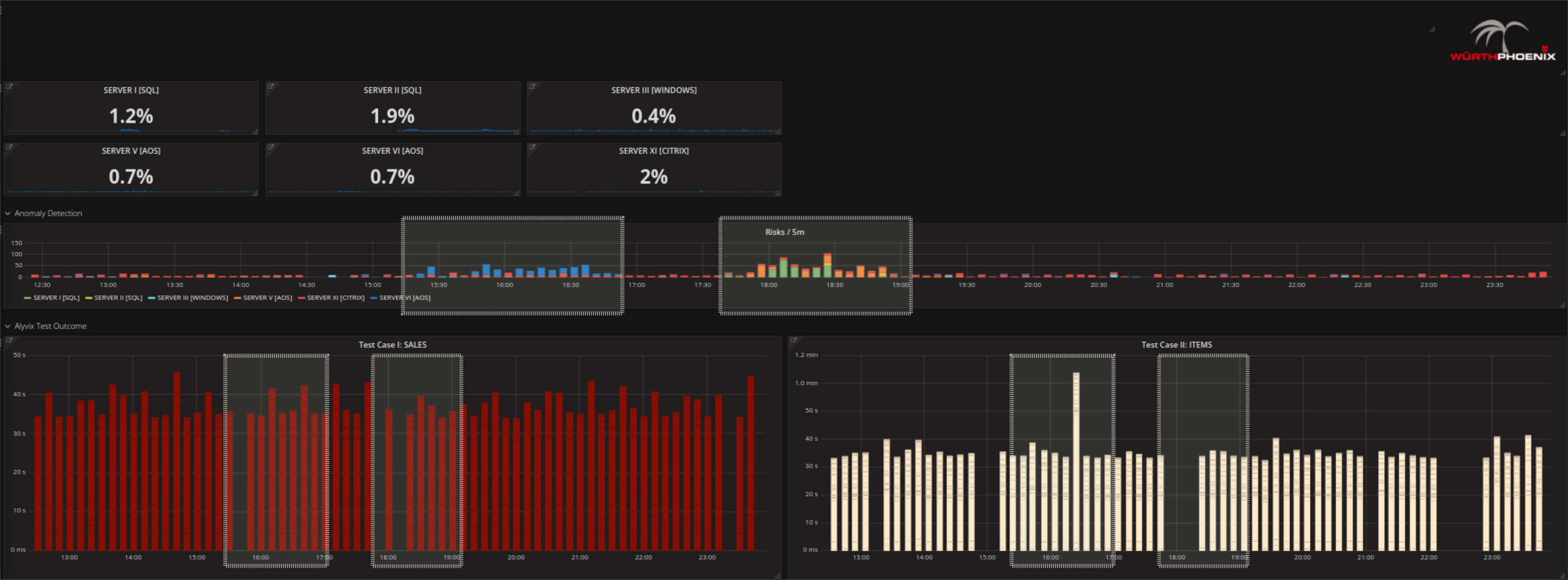
- Kontrollieren Sie mit Alyvix und Anomaly Detection ob tatsächlich ein Problem vorliegt: Ja, könnte sein. Alyvix zeigt sowohl einen Test mit erkennbaren Verzögerungen, als auch einen Abschnitt in dem keine Daten aufgezeichnet werden konnten.
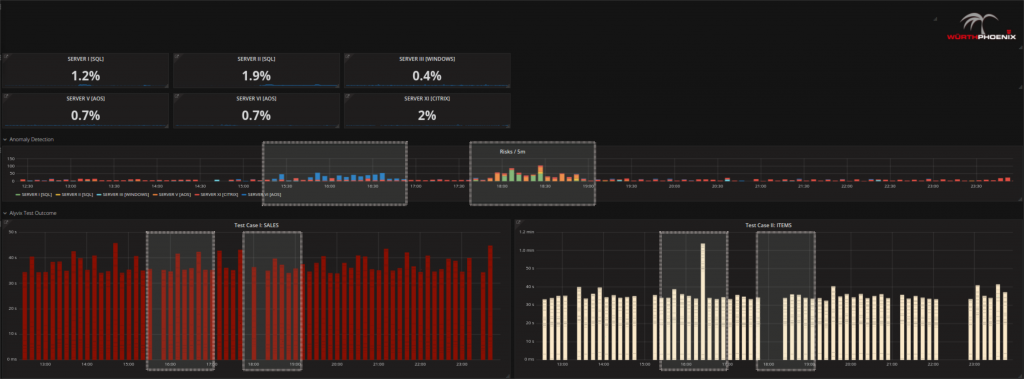
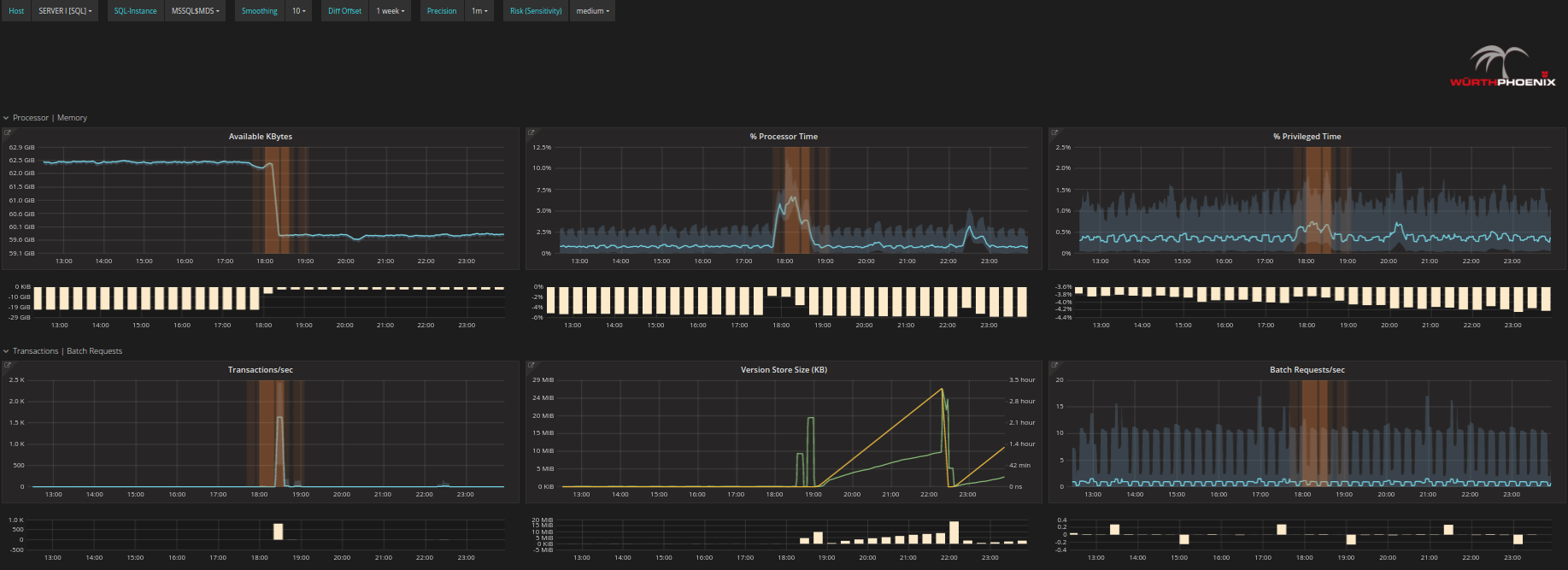
- Versuchen Sie zu erkennen woher das Problem kommt: Sollten Sie bereits einen bestimmten Server verdächtigen, klicken Sie auf den Server Overview Tab um zum Server zu navigieren. Alternativ können Sie über die erkannten RISKs scrollen und von dort aus Drill Downs vornehmen.
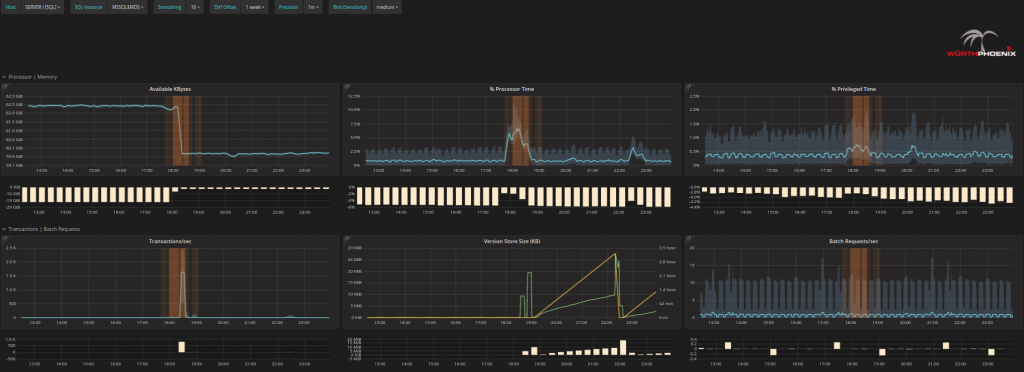
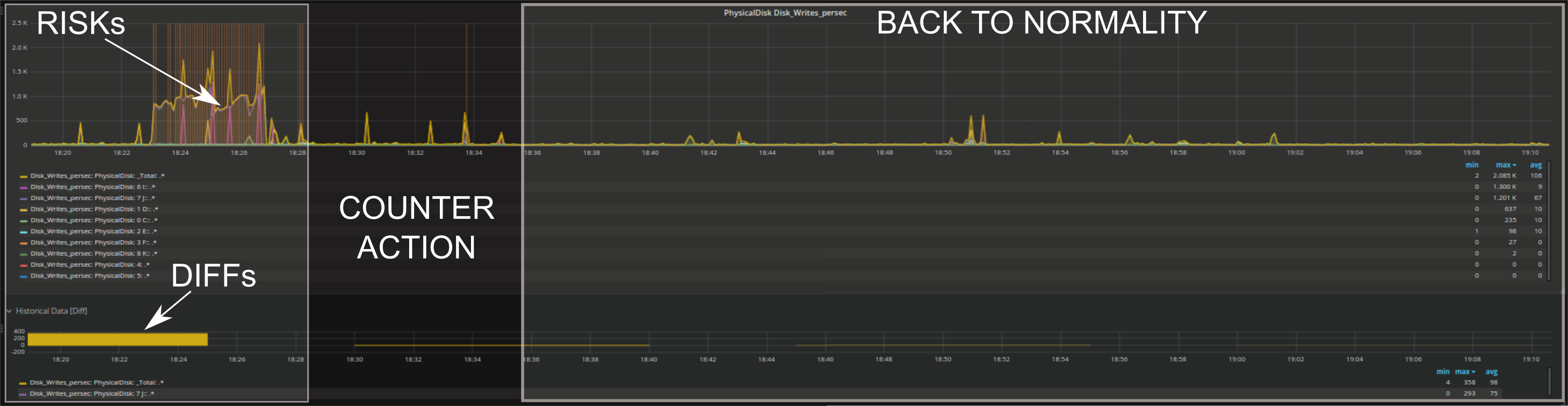
- Analysieren Sie das Problem im Detail: Es ist möglich in jedes Problem genauer hinein zu zoomen, bis hin zum genauen Verhalten einzelner Disks oder einzelner Prozessorkerne. Auf diese Weise kann im Detail überprüft werden, was gerade geschieht bzw. geschehen wird,
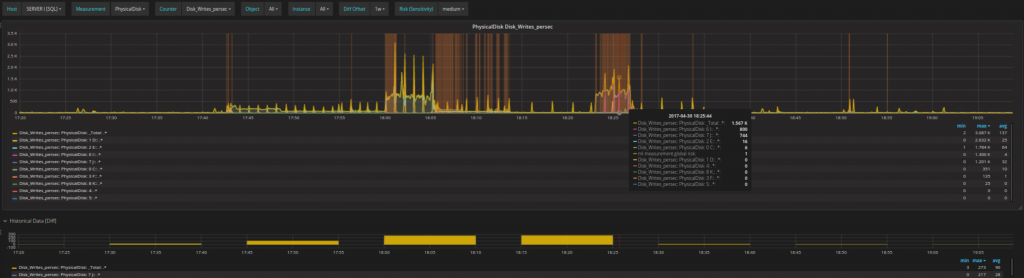
- Beheben Sie das Problem und suchen sie nach Möglichkeiten zukünftig ähnliche Probleme zu vermeiden: Sie erkennen sofort ob Ihre Gegenmaßnahmen die Situation verändert haben.
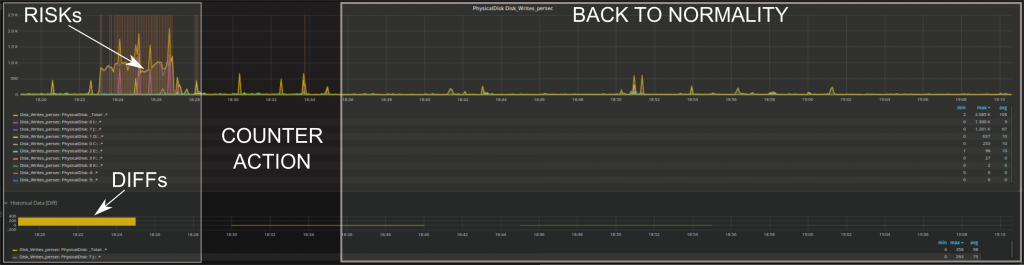
Wie Sie sehen, wurde Anomaly Detection in Form von RISKs implementiert. Ein RISK ist in diesem Zusammenhang alles was vom Standard abweicht. Standard Methoden (Bsp.: Baselining) haben eine Art und Weise wie sie Abweichungen auffassen, sie erkennen nur Events die stark von den Standardwerten der einzelnen Metriken abweichen. Anomaly Detection ist hingegen in der Lage verschiedene Arten von Veränderungen zu erfassen und ist zusätzlich auch sehr dynamisch.
Der Vorteil der Erweiterung des Next Level Performance Monitoring um die Anomaly Detection wird somit deutlich: RISKs können die Suche nach den kritischen Zeitabschnitten beschleunigen. Aufgrund der erhöhten Wahrscheinlichkeit einer Verbindung zur Root Cause, können jene Abschnitte – die anders erscheinen – während des Troubleshootings als erstes berücksichtigt werden. Multivariate Statistik macht es möglich das Verhalten vieler Metriken zu analysieren UND mögliche Verbindungen zwischen Ihnen zu erforschen, während das menschliche Auge nicht in der Lage ist, mehr als einige wenige Metriken gleichzeitig zu bewerten. Anomaly Detection Algorithmen können noch leistungsstärker gemacht werden indem immer mehr Informationen über die System Performance Metriken hinzugefügt werden. Das geschieht durch dynamisches Lernen von historischen Daten oder durch die Integration von Erkenntnissen immer dann, wenn eine Fachkraft aufgrund der vorliegenden Daten eine Entscheidung fällt. Alles in Allem kann behauptet werden, dass Anomaly Detection in unserer Lösung aktuell als Indikator dafür verwendet wird, wo als erstes nach dem Problem gesucht werden soll. Das zu erwartende Ergebnis kann mit den Alerts die auf herkömmliche Weise generiert wurden übereinstimmen, es ist aber auch möglich, dass andere ebenfalls gefährliche Konstellationen erkannt werden bevor das tatsächliche Problem auftritt. Außerdem kann das Output von Anomaly Detection mit den Standard Alerts kombiniert werden, um mehr oder weniger relevante Events herauszufiltern.

Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix