10. 07. 2026
APM, Log Management, Log-SIEM

Rarely has a title been more fitting: Transform metrics into alerts. It’s not just a description of what the system does – it’s also the exact name of the Elastic tool that makes it possible. Transforms, in their technical meaning, are the component we use to do precisely this: take a continuous stream of raw metrics and transform them, process them, give them meaning – all the way to producing the status of a monitoring service. The title is not a metaphor: it is a literal description.
So, the project I’m going to describe was made possible by the use of Transforms, a native Elastic feature that was however applied with a completely new approach, never before attempted in this context. This isn’t a conventional use of the tool, but a creative reinterpretation of its potential, which allowed us to build a massive, scalable and flexible monitoring system starting exclusively from already existing metrics.
The Context: Where the Project Begins
The starting use case is extremely simple: a client already collects and stores metrics from all its devices – network equipment, access devices and customer terminals included – for consultation purposes. The goal is to leverage these metrics to determine the health status of the devices sending them, without querying them again through plugins or other external systems.
The collected metrics are numerous, not only in quantity but also in variety. The required monitoring checks range from relatively simple ones – such as CPU and memory usage – to significantly more complex situations: spikes in the number of connected users, BGP route and peer status, various sensor readings, and much more. It’s a variety that made the project technically challenging from the very beginning.
A crucial element that shaped the architectural decisions from the outset was the vastness of the perimeter: the number of objects to monitor and the sheer quantity of checks to perform made a traditional active monitoring approach simply impractical – or at least not entirely sustainable. Querying every device directly and repeatedly, at the required frequency and across the full scale of the client’s infrastructure, would have generated an unsustainable load.
We thus decided to take the path of passive monitoring, leveraging the Elastic ecosystem already in place: rather than asking devices for their status, the metrics themselves – already collected and stored – are left to tell the story.
My Contribution: The Elastic Ecosystem
Within this project, I was responsible for the entire Elastic ecosystem: from designing the ingest flow to building the processing logic and connecting it to the alerting system.
For this client, the Logstash infrastructure is structured around two distinct components: on one side the PCS resource, representing the clustered Logstash integrated into the NetEye architecture – used in particular for those metrics that, by their nature, cannot be distributed across multiple nodes and therefore require a centralized processing point – and on the other a Standalone component, introduced to address specific performance and workload separation needs that we will explore later.
The Entry Point: Standalone Logstash
The first block we encounter is the Standalone Logstash, the single entry point for all metrics into the system. All data arriving from the infrastructure – after their journey through Telegraf and Kafka – is delivered to this Logstash instance, whose sole purpose is to receive them reliably, queue them to disk, and route them to Elasticsearch.
At this stage, no monitoring logic or complex transformations are applied yet: the goal is to ensure that the flow is stable, persistent and scalable, so that all subsequent processing steps can then be safely applied directly in Elasticsearch.
To implement this, an NGINX VIP sits in front of the Logstash nodes acting as a reverse proxy and load balancer: it receives incoming metrics and distributes them across the 3 active standalone nodes. A health check periodically verifies the status of each node: if one stops responding, traffic is automatically shifted to the others (failover) and, once it recovers, it re-enters the rotation. Each Logstash node has a persistent disk queue to absorb traffic spikes or temporary interruptions. Once ingested, events are forwarded to Elasticsearch.
Data Processing: Transforms
The core of the processing are the Transforms. Before starting the project, they were a practically unknown tool, often described simply as “Excel pivot tables”. By studying them in depth, it became clear that they’re extremely powerful and capable of implementing even quite complex logic.
Thanks to this component, it’s possible to build scripts similar to those Icinga runs every few seconds on a given device, but applied massively across all devices and at shorter intervals.
A Transform consists of a query, whose result can be manipulated and managed by an Ingest Pipeline, and then sent to a dedicated index with retention management.
The Heart of the Transform: Ingest Pipelines
Ingest Pipelines are the true heart of every Transform. For each element selected by the query, a pipeline can be applied to define the actions to perform: calculations, transformations, field additions or removals. In the context of this project, Ingest Pipelines are used to produce the final output and handle error management. A practical example is calculating CPU load: for each incoming metric, the pipeline identifies the host, applies comparison logic, and checks the value against defined thresholds.
The Threshold Problem: The Lookup Index
A question then immediately arises: how do we dynamically associate metrics with services and define warning and critical thresholds? Hard-coding them inside every pipeline would not be flexible enough. The solution we adopted is as follows:
In Director, custom variables are added to Service Templates containing the name of the Transform to associate, along with some configuration parameters such as warning and critical thresholds. These templates are used to create Service Objects, Service Sets and Service Apply Rules. The information is then propagated to Icinga via deploy.
At this point, through a script running every 15 minutes, this data is inserted into an Elasticsearch index, making it available to the Transform Ingest Pipelines. For each incoming metric, the pipelines search this index for any linked services: if found, they extract the service name and parameters and use them to process the metric itself. In this way, the monitoring status is calculated only for what is needed, using parameters defined by the client, without the client ever having to touch Pipelines or Transforms.
From Data to Alert: The Elastic-Icinga Connection
At this point, Elastic has a complete snapshot of the status of all objects, with one document per Host/Service pair of interest. The handover to Icinga happens through a script that every minute extracts the latest version of all these documents and sends them to Icinga via Tornado.
This part of the project was not handled directly by me, but by a colleague who took care of the integration between Elastic and Icinga. I describe it here for completeness, to provide an end-to-end view of the flow.
All documents share the same structure, so it’s sufficient to send them all to a single Webhook and process them with a single rule. This rule executes an appropriate Process Check Result on the indicated service. There’s no need to use the Smart Monitoring Action, because all Host/Service objects of interest are already present in Icinga and don’t need to be created dynamically – eliminating performance concerns and allowing the standard dependency logic, notifications, Business Processes and everything else to work exactly as in traditional active monitoring.
Services are configured as passive with freshness: this way, if metrics from a host stop arriving for long enough, one or more UNKNOWN states will signal to the client that metrics are no longer being received.
The Technical Challenge: Derivative Calculation
One of the most significant challenges encountered during the project was derivative calculation. In many monitoring scenarios, observing the derivative trend of a metric is extremely useful for detecting sudden spikes or anomalies.
The problem is that, in the version of Elastic in use at the time of the project, there was no native command for derivative calculation – a feature that other platforms such as InfluxDB already offered natively. An alternative solution therefore had to be found.
The solution? Calculating the derivative manually, exactly as taught at university: given two consecutive points in time, the derivative is simply the change in value divided by the change in time – the classic incremental ratio:
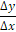
Thankfully, mathematics was always a subject I enjoyed, and it was precisely this background that allowed us to unblock the situation.
Performing this calculation massively across all devices through Logstash required a lot of memory however, causing the process to crash. The first solution was to separate responsibilities: introduce the Standalone Logstash to handle metric collection, freeing up resources for the clustered Logstash (PCS) dedicated to computation. This allowed the calculation to run more stably, but performance still wasn’t satisfactory and data was arriving later than desired.
The next step was to develop a battery of Transforms to further speed up the calculations. The result was remarkable: loading the full derivative history went from taking weeks down to just a few hours for a single metric.
Conclusion
This project wasn’t easy. Between unexpected technical challenges, platform constraints and the need to reinvent established approaches, there were moments when the road felt more uphill than down. But it’s precisely at those moments that the most interesting solutions are born. In the end, seeing a massive monitoring system work – powered exclusively by already existing metrics and a tool used in a completely new way – brought a level of satisfaction that made every difficulty encountered along the way worthwhile.
If you’re curious to learn more about this approach or would like to explore how to apply it in a similar context, feel free to reach out. I and my colleagues who worked with me on this project are available to answer any questions and to help you evaluate whether this solution could be the right fit for your needs.
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Our customers often present us with problems that need customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth IT Italy.
Franco Federico
Hi, I’m Franco and I was born in Monza. For 20 years I worked for IBM in various roles. I started as a customer service representative (help desk operator), then I was promoted to Windows expert. In 2004 I changed again and was promoted to consultant, business analyst, then Java developer, and finally technical support and system integrator for Enterprise Content Management (FileNet). Several years ago I became fascinated by the Open Source world, the GNU\Linux operating system, and security in general. So for 4 years during my free time I studied security systems and computer networks in order to extend my knowledge. I came across several open source technologies including the Elastic stack (formerly ELK), and started to explore them and other similar ones like Grafana, Greylog, Snort, Grok, etc. I like to script in Python, too. Then I started to work in Würth Phoenix like consultant. Two years ago I moved with my family in Berlin to work for a startup in fintech(Nuri), but the startup went bankrupt due to insolvency. No problem, Berlin offered many other opportunities and I started working for Helios IT Service as an infrastructure monitoring expert with Icinga and Elastic, but after another year I preferred to return to Italy for various reasons that we can go into in person 🙂 In my free time I continue to dedicate myself to my family(especially my daughter) and I like walking, reading, dancing and making pizza for friends and relatives.
Author
Latest posts by Franco Federico
10. 03. 2026
Unified Monitoring
Elastic AutoOps in NetEye: Simplifying Elasticsearch Operations with Real-Time Intelligence
09. 09. 2025
NetEye
Backing up a MariaDB Galera Cluster
12. 06. 2025
NetEye, Unified Monitoring
From Monitoring to SOC
17. 02. 2025
Unified Monitoring
Monitoring Printer Logs