15. 06. 2026
NetEye, Unified Monitoring

The code is the structure, the LLM is the glue at the joints.
There’s a widespread misconception about automations “powered by artificial intelligence”: people picture a model you give an order to, which then carries out a complex operation from start to finish all on its own. It’s a seductive image, and almost always wrong. The automations that truly work, the ones you ship to production and that don’t betray you at night, are built on a far more sober principle, and once you see it you never forget it.
The core idea
An LLM-assisted automation is not an intelligence that “does everything”. It’s a deterministic pipeline, a sequence of predictable, repeatable steps, in which the model is consulted only at the junction points where rigid code can’t cope: interpreting a natural-language request, reading unstructured input, choosing between alternatives, translating from one format to another.
Put as an image: the code is the structure, the LLM is the glue at the joints. The guiding principle that follows is just one: separate what must be done (the deterministic spec) from judgment (the LLM). Everything else is implementation detail.
It’s also why these automations work even with small models running locally on modest hardware: every single question put to the model is tiny and tightly bounded. The intelligence isn’t in the model; it’s in the scaffolding you build around it.
The building blocks
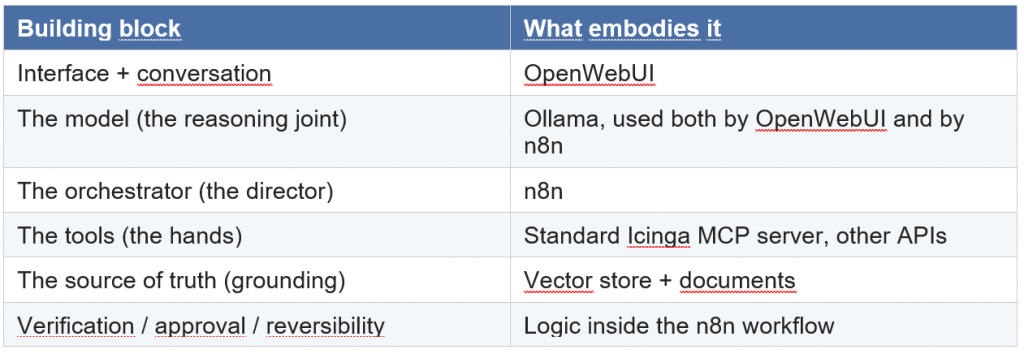
Six components. Once you recognize them, you’ll find them in any serious automation.
- A goal broken into steps. Before writing a line, the operation is split into discrete steps. And for each one you ask a single question: is this step deterministic, or does it need judgment? You’ll find that the vast majority of steps need no model at all: they’re data reads, transformations, writes. This exercise alone is half the work.
- The tools, “the hands”.The system must have a repertoire of deterministic actions it can perform precisely: calling an API, querying a database, reading and writing files. Each with a clear contract of inputs and outputs. The golden rule is that the model never touches the real system: it asks a tool to do it. That way the action stays exact and verifiable, regardless of what the model may have “thought”.
- The source of truth. The model shouldn’t remember how your system is built: it should read it at the right moment. Documentation, schemas, lookup tables, examples: all of this is fetched at runtime and placed in front of the model only when needed. It’s the difference between an assistant that invents plausible-but-false command names and one that answers from the facts in front of it.
- The orchestrator, the director. Someone has to drive the flow: decide the next step, hold the state, handle errors, know when to stop.
- Verification and self-correction. Every action is checked immediately: did it produce the expected result? If not, the error goes back to the model, which retries with that extra information. It’s this closed loop, not the model’s power, that produces reliability.
- Safety and reversibility. A dry run before applying for real, human intervention on risky operations, the ability to roll back, a log of what was done, least privilege. It’s what separates a toy from something you put into production.
How they connect: the frontend and the backend
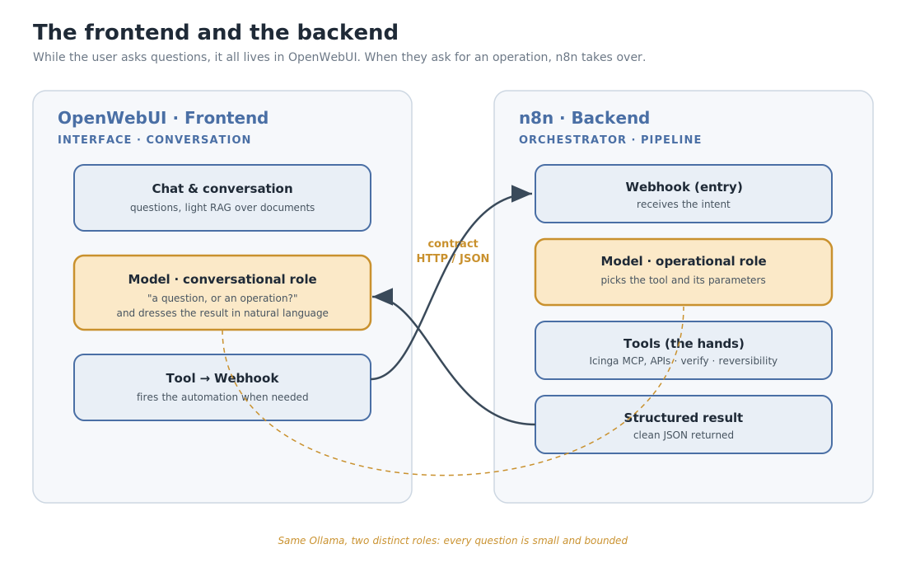
The building blocks, on their own, are concepts. They become concrete when you place them on real tools. A very common combination, and fully self-hosted, is OpenWebUI as the interface and n8n as the orchestrator. With this stack the roles split very cleanly:
- OpenWebUI is the frontend It’s the chat, the conversation, the optional light RAG over documents, and the model’s first decision: “is this a simple question I answer, or an operation to kick off?”.
- n8n is the backend It’s the deterministic pipeline that runs the actual operation. In n8n the workflow you draw is the scaffolding made visible: the AI node is the joint where you consult the model, the request nodes are the hands, the verification and wait nodes are the guardian and the approval points. The huge advantage, especially in a real work setting, is that the flow becomes readable and editable by anyone, not buried in lines of code only one person can touch.
Here’s the full map:
When n8n comes into play
OpenWebUI offers a Tools mechanism: during the conversation the model can decide to invoke an external tool, in our case an n8n webhook. The boundary is sharp:
As long as the user asks questions, everything lives inside OpenWebUI. The moment they ask for an operation, the model fires the tool → the call to the webhook starts → from there on n8n is in command.
That boundary is a simple HTTP/JSON contract: the intent in, a structured result out. Clean and swappable: tomorrow you change the interface and n8n doesn’t even notice.
Note. There’s also the inverse pattern: hooking directly into n8n from OpenWebUI, configuring the workflow as if it were the “model” you talk to (via an OpenAI-compatible Pipe). In that case every message enters the pipeline right away. It’s more powerful, but it blurs the roles a bit; for clarity, here we describe the “n8n behind a Tool” pattern.
The detail that clears everything up: the model appears twice
This is the most important thing to grasp. The same model (the same Ollama) works in two distinct roles:
- Inside OpenWebUI, in a conversational role: it understands the sentence is an operation, decides to call the automation, and in the end dresses the result in natural language.
- Inside n8n, in an operational role: it picks the precise tool and fills in its parameters.
These aren’t two intelligences: it’s the same model consulted for two micro-decisions, each small and bounded. That’s exactly why it works even with a modest model.
The rhythm that ties it all together: a cycle
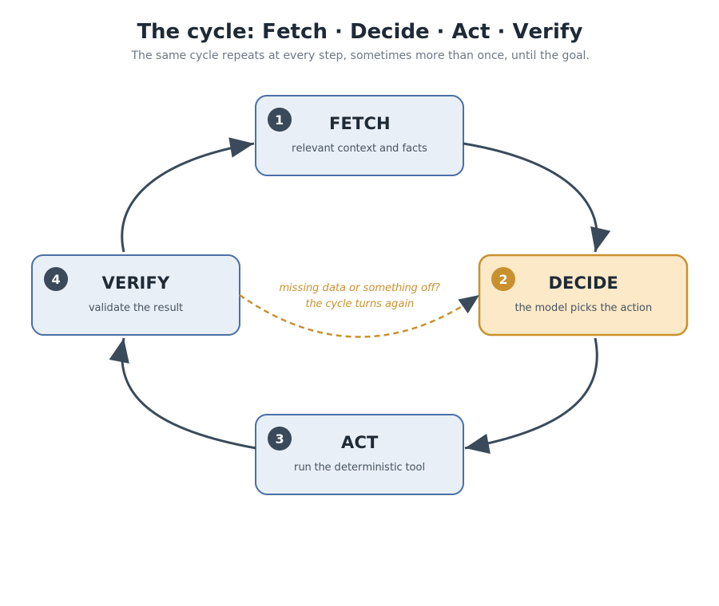
At every step, inside the backend, the same cycle repeats:
- Fetch the relevant context and facts.
- Decide: the model picks the action and its parameters, on the fetched facts alone.
- Act: the orchestrator runs the deterministic tool.
- Verify: the result is validated; if a piece is missing or something is off, the cycle turns again.
Fetch, decide, act, verify. The important thing is to read it as a cycle, not a straight line: each turn brings home one piece of information and, if answering needs more, the wheel turns again, until the final result comes together. We’ll see exactly this in the example below, where the cycle makes two turns.
A concrete example
Imagine a request posed by an operator in the OpenWebUI chat:
“Which hostgroups contain hosts with services in error?”
Let’s assume the system is connected to the standard Icinga MCP server, which exposes a catalog of ready-made tools: get_services, get_services_with_problems, get_hosts_with_problems, get_hostgroups. Notice a small catch right away: the operator asks for hostgroups, but the natural starting point is the services in error. Between the two sits the membership of hosts in groups. That’s why the cycle will have to turn twice.
First turn: find the hosts in trouble
Fetch. The model is shown the catalog of tools with their descriptions, and the fact that “in error”, in monitoring language, means “with problems” (the WARNING/CRITICAL/UNKNOWN states).
Decide. Here, and only here, the model steps in. Its sole task is to pick the right tool. Between get_services (all services) and get_services_with_problems (only the problematic ones), “in error” leads it to the second:
{ "tool": "get_services_with_problems" }It doesn’t make the call, doesn’t invent hostgroup names, doesn’t reason over the results.
Act. The orchestrator actually invokes get_services_with_problems on the Icinga MCP server. Back comes the list of services in error, each with the host it belongs to. From this we derive the set of hosts in trouble: the hosts that have at least one problematic service.
Verify. We have the hosts, but the question didn’t ask for hosts: it asked for hostgroups. A piece is missing, the host→hostgroup membership map. The cycle isn’t done: it turns again.
Second turn: link hosts to groups and give the answer
Fetch and act. This time there’s no need to bother the model: the goal “which hostgroups” predictably requires the membership map, so the orchestrator calls get_hostgroups directly. For each hostgroup it returns the list of its member hosts. (Often this data is already in the host object from the first turn; when it is, the second turn is skipped.)
Relate them: this is where the two lists are joined. Now the deterministic code does the work that makes sense of everything. For each hostgroup it checks whether at least one of the hosts in trouble appears among its member hosts: if so, that hostgroup enters the answer; if not, it’s discarded. In practice it’s an intersection of two sets, the hosts in error and the members of each group:
problem_hosts = { s.host for s in get_services_with_problems() }
answer = [ g.name
for g in get_hostgroups()
if problem_hosts & set(g.members) ]
return sorted(set(answer)) # deduplicated and sorted
Verify and shape. The resulting hostgroups are deduplicated and sorted: this list, and only this, is the single piece of information the operator asked for. If the intersection is empty, the system answers “no hostgroups affected”; it doesn’t ask the model to “make up” a plausible answer.
The takeaway is in the division of roles: the model only picked the right tool from an ambiguous sentence; all the real work (invoking the tools, gathering the services, fetching the hostgroups and above all joining them to keep only the groups with hosts in error) was done by deterministic code and the Icinga MCP server.
The same example, inside n8n
Here’s how that cycle takes shape as an n8n workflow: six nodes, one per role.
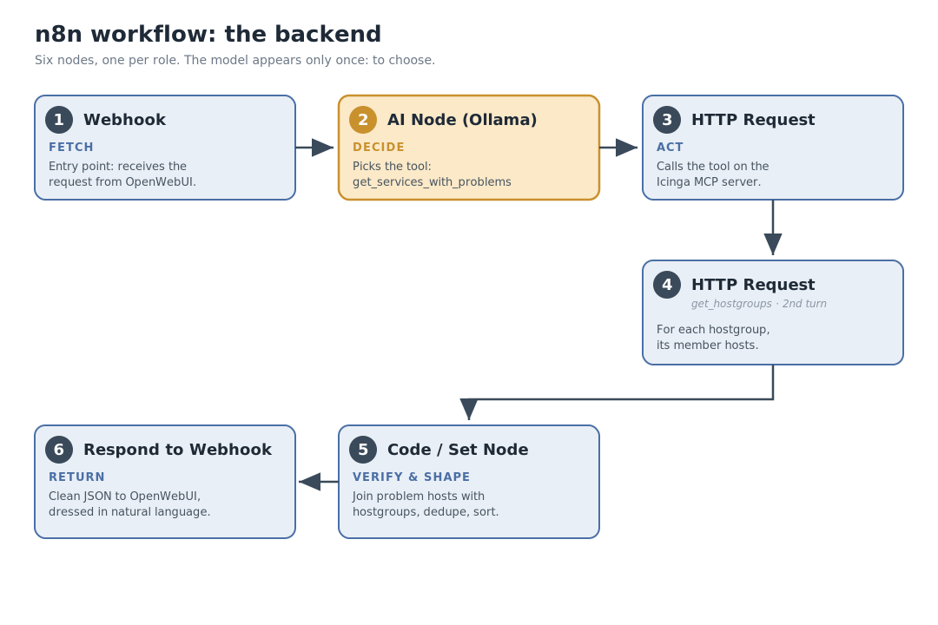
- Webhook: it’s the entry point. It receives the user’s request from the OpenWebUI call. Here the backend begins.
- AI Node (Ollama): the DECIDE joint. It receives the question and the tool catalog, and produces the structured choice (get_services_with_problems). It’s the only point where the model steps in inside the workflow.
- HTTP Request → Icinga MCP: the ACT step. It calls the chosen tool on the MCP server and gets the services in error with their respective hosts.
- HTTP Request → get_hostgroups (the second turn of the cycle): for each hostgroup, it fetches its member hosts. Often the data is already in the host object from the previous step, and then this node is skipped.
- Code / Set Node: the VERIFY and shape step, fully deterministic. It joins the hosts in error with the members of each hostgroup, keeps only the groups that contain at least one, deduplicates, sorts, and handles the “no problems” case.
- Respond to Webhook: it returns a clean result to OpenWebUI, which the interface model dresses in natural language for the user.
Notice what isn’t there: no “do everything with AI” node. The model appears just once, for a single choice. Everything else is scaffolding. And if you change the question, “the unreachable hosts” instead of services in error, only the output of node ② changes, from get_services_with_problems to get_hosts_with_problems; the workflow stays identical.
In conclusion
Building an LLM-assisted automation doesn’t mean finding the most powerful model and hoping. It means designing solid scaffolding (a frontend that converses, a backend that executes, precise tools, facts within reach, a guardian that verifies) and entrusting the model with only what it does best: understand, choose, translate. It’s a simple shift in perspective, but it’s everything: the automation’s intelligence isn’t in the model, it’s in how you put it to work.
From here on: getting serious
What we’ve described is the base, the starting point: scaffolding in which the model chooses and the code executes. It’s the best way to understand how these automations really work, and it’s enough to ship concrete cases like the hostgroup one to production. But it’s only the first step.
The moment you want to start getting serious, there are far more sophisticated and automatic approaches, built around genuine reasoning engines: models that, given the goal and the catalog of available tools, plan the sequence of steps on their own, build the needed commands and «recipes» on the fly, chain multiple calls, evaluate intermediate results, and correct course without the flow having been drawn by hand. There the scaffolding doesn’t disappear, but it becomes more dynamic: part of the logic we wrote here is generated and orchestrated by the model itself. It’s a fascinating, fast-moving territory (agents, planners, automatic tool-use, ReAct and the like), with different trade-offs around predictability, cost, and control.
But that, as they say, is another story.
Andrea Mariani
Author
Latest posts by Andrea Mariani
21. 03. 2026
AI
Reflections on Running LLMs Locally: Why It’s Worth Running Them on Your Own Infrastructure
11. 09. 2025
NetEye, PHP, Unified Monitoring
Using Keycloak to Secure Web Pages and Virtual Directories
20. 06. 2025
NetEye, Unified Monitoring
NEP Telegram Notification