





16. 02. 2026
Unified Monitoring

30. 09. 2025
Marco Berlanda
Development, DevOps, Kubernetes
A GitOps Path from Code to OpenShift Cluster
A modern web app isn’t one single big monolith: it’s made of quite a lot of pieces!
For instance, we relied on a setup such as this one for a recent one we are developing:
- An API that generates its own OpenAPI spec
- A frontend that builds a typed client from that spec
- Database migrations
- Optional seed data
- And even an accessibility report viewable online
That’s a lot of moving parts. You could glue them together with scripts, sticky notes, and caffeine… but then most likely only one person will know how it actually works, and that person is usually on holiday when it breaks (oooh and it will, trust me).
So we took a different path: we decided to treat every piece as its own proper build artifact, and thus wire the pipeline so promotion is pretty much “on rails”: build → tag → deploy → done.
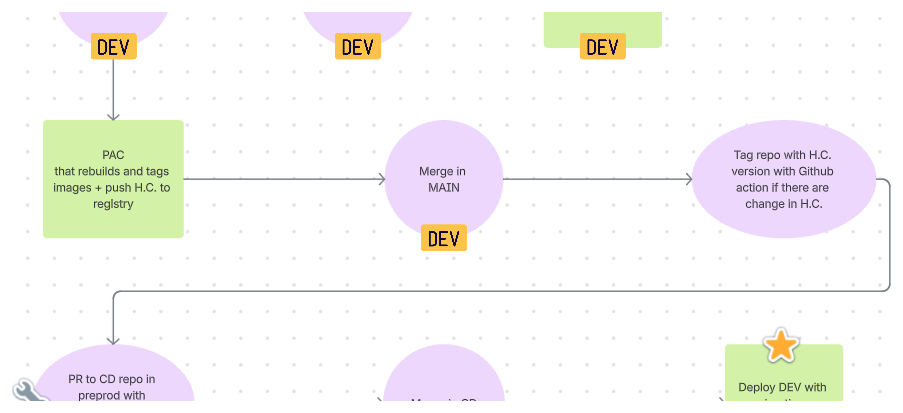
Here’s the flow, the design choices, and the pitfalls we had to dodge along the way.
Build Artifacts: Everyone Gets Their Own
The pipeline-as-code spits out separate images for:
- Migrations (DB schema updates)
- Seed data (optional demo population, needed to run tests on the PAC)
- API (backend + OpenAPI spec)
- Frontend (static VueJS app with generated client)
- A11y report (static accessibility report)
Why separate them you ask? Because bundling them together is how you end up with five replicas all “helpfully” running migrations at the same time. Man, do you even care about your own mental health??
By giving each concern its own image, the promotion strategy is dead simple: build once → deploy many.
Next, let’s look at how the API and frontend stay perfectly in sync without hand-holding.
OpenAPI Never Lies
During the API build, we generate an OpenAPI spec and bake it right into the image. This way, the frontend pulls that spec from the API built image and generates its client.
This means API and frontend literally cannot drift apart. No stale files, no “oh, I forgot to re-run the generator.” Just a solid and simple factory-chain between backend and frontend.
With the contract locked down, it’s time to talk about migrations and why they deserve their own spotlight.
Why Migrations?
Migrations get their own job. That means:
- They’re versioned with the code
- They run once, in a controlled way
- They never sneak in at app startup
Without this, you get the classic “works on my machine”: someone adds a column locally, forgets to commit, and suddenly prod goes… BOOM. And not the fun kind of boom.
Now, if the migration image wasn’t built, the change simply doesn’t exist.
Also, if you’re the kind of person that makes “just small changes manually” on a DB of any kind, I strongly advise you to check this place out for your next vacations.
Seed Data is Good (Sometimes)
Seed data is great for demos and test drives, but obviously quite terrible if it accidentally sneaks into production.
That’s why seed logic is its own artifact, switchable by config, and ephemeral by design. It fills tables, doesn’t alter schema, and vanishes when done.
With the DB in shape, it’s worth looking at another often-overlooked piece: accessibility.
Transparency is Great
Most teams treat accessibility checks as disposable CI noise. We treat them like receipts.
The results get baked into a deployable static image. That makes them reproducible, hostable, and tied to the release they belong to.
It’s not meant to be used as “proof” that they passed (you shouldn’t need that at all if you’ve built a solid PAC) but it’s more to highlight how actually compliant our app is. No silenced warning or shady sleights of hand!
Helm: Time to Deploy!
We can think of the Helm chart as the runtime blueprint: it knows what belongs in the cluster, how it should start up, and in what order. Database, API, front-end, accessibility report, migrations, seed jobs: all of them are described and kept in line here.
The magic trick? One tag to rule them all. Everything (from jobs to services) ships with the same version number. That means when someone inevitably asks “what’s running in prod right now?”, you don’t need to go spelunking through logs or guess which container is lagging behind. The answer is just the tag.
Clean, super easy and reliable.
Helm charts deployed, but what’s the actual flow from Git tag to running cluster?
Let’s break it down.
The Flow (Boring on Purpose)
Diagram caption: Build → Tag → Push → Deploy → Hooks → Running cluster
- Push a Git tag
- CI builds all images with that tag (API first)
- Images go to the registry
- Helm/Argo sees the new version and applies it
- In order:
- Database spins up
- Migration job runs
- Optional seed job runs
- API deploys (with health checks)
- Frontend waits for API before starting
- Accessibility report deploys
- Routing layer connects the dots
That’s it. Nothing clever, nothing fancy. And that’s the point.

Avoid convoluted loops and too many conditional loops or “special” cases. This should be the most solid, reliable and robust thing you can think of.
The tricky part here is to foresee the future needs of your app, to design it in such a way that you won’t have to destroy and rebuild half of it 3 months from now. Which sounds very obvious and easy but it really is not. At all.
Hooks Are Your Friends!
Migrations use a sync hook, so they run as part of deployment and not as a “we’ll get to it later” kind of step.
Seed jobs use a post-install hook, so they run once and don’t keep dropping demo data into live environments.
The takeaway here is that everything should be precisely pinned and in sync with everything else, avoid any sort of “casual” behavior from any part of your engine. Part B should start when Part A is done, Part C after Part B and so on…
So, let’s see what the cluster actually looks like in action.
When the Dust Settles…
When the pipeline finishes running, you’ve got:
- A persistent database
- Deployments for API, frontend, and accessibility report
- Ephemeral jobs for migrations and seed
- Services for routing inside
- A single routing layer outside
And all of it stamped with the same version tag. Holy cow!
Why It Works (And Keeps Working)
This setup avoids the usual traps:
- Build-time only: artifacts generate clients and specs before shipping, never at runtime. Never, don’t.
- Controlled migrations: schema changes run as jobs, not hidden inside app startups. Also idempotent obviously.
- Immutable artifacts: a new tag is the only path to a new rollout/deployment. Clear and predictable.
- Explicit dependencies: hooks and probes define a precise order and readiness. No room for random stuff.
It’s intentionally “boring”. Mostly because boring pipelines have the subtle quality of not waking you up at 2 AM. Just the way I like them.
Time to Wrap Up!
By separating migrations, seed data, contract generation, and extra assets like accessibility into their own clean boxes, Our Web App’s pipeline is easy to explain and easy to trust.
Argo CD just keeps state in sync (and performs the actual deployment) – the real win was making that state unambiguous.
The result? Consistent deployments, a backend and frontend that never clash, and a pipeline that feels refreshingly drama-free.
If this doesn’t feel impressive to you, I’m pretty sure you’re reading the wrong blog, pal. Why are you even here??
As our journey through OpenShift takes us to new and amazing places, I’ll make sure to share all of our adventures with you all.
In the meantime, thank you for reading this!
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Programming is at the heart of how we develop customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.
Marco Berlanda
UX Front-end engineer by day, UX wizard by night, and an Interaction design ninja all the time. Always on the hunt for those ‘wow, didn’t see that coming!’ solutions to problems.
Author
Latest posts by Marco Berlanda
18. 12. 2025
Development, Front-end, UI, Vue
API Contracts Don’t Protect Vue 3 Frontends… Integration Tests Do
24. 06. 2025
Development, Front-end, UI, UX, Vue
Reactivity Troubles: When Vue’s Magic Backfires
12. 04. 2025
Development, Front-end, UI, UX
Please STOP Designing for Failure: How Optimism Can Transform Your UX
29. 10. 2024
Front-end, Real User Experience, UI, UX
The Power of Micro-Interactions: Enhancing UX in Front-end Development