





02. 04. 2026
NetEye, Unified Monitoring

30. 09. 2025
Damiano Chini
APM, Development, NetEye, Unified Monitoring
Segregating APM Data in Elastic: A Practical Guide to a Not-So-Obvious Challenge
If you’ve worked with Elastic APM, you’re probably familiar with the APM Server: a component that collects telemetry data from APM Agents deployed across your infrastructure. But what happens when you need to segregate that data by tenant, especially in complex network zones?
Let’s walk through a real-world scenario and how we tackled it.
The Simple Case: One Tenant per Edge
In the ideal setup, each Fleet-managed APM Server sits at the edge of your infrastructure and collects data from a single tenant. In this case, segregation is straightforward: assign the APM Server to a dedicated namespace (e.g., my_namespace), and all data it collects will be stored there. You can then define roles that restrict access to that namespace, ensuring data isolation.
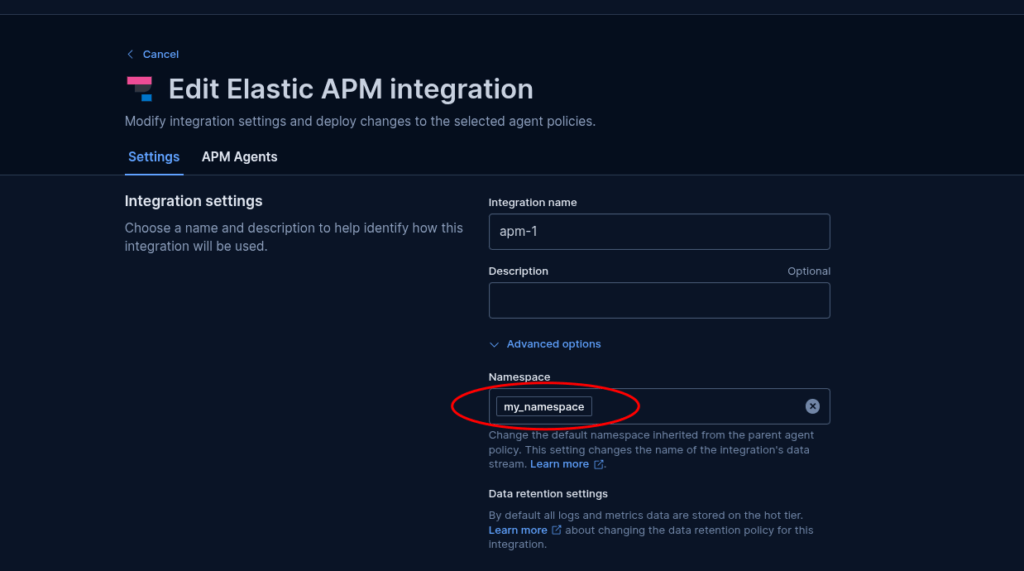
Seems easy, right? But things get interesting when multiple tenants share the same network zone.
The Complex Case: Multiple Tenants, One Edge
Now imagine an edge server that needs to collect data from multiple APM Agents, each belonging to a different tenant. This isn’t common, but it does happen, and it complicates things.
Elastic currently allows only one namespace per APM Server integration, and you can’t deploy multiple APM Servers on the same Elastic Agent. So how do you segregate data in this scenario?
We explored a few options.
Option 1: Multiple Elastic Agents
One idea was to deploy multiple Elastic Agents on the same edge server, one per tenant. Each Elastic Agent would run its own APM Server, configured with a different namespace.
Technically feasible, but we quickly ran into some issues:
- Resource Overhead: Running multiple agents and APM Servers increases CPU and memory usage.
- Operational Complexity: We’d need to containerize the agents, manage port bindings to avoid collisions and configure each APM Agent to send data to the correct port.
- Security Concerns: Without using secret tokens, any APM Agent could send data to any namespace. Agent Keys alone would not enforce strict segregation.
Due to these drawbacks, we ruled out this approach.
Option 2: Rerouting via Ingest Pipelines
Next, we looked into Elastic ingest pipelines, as suggested in this article. The idea was to reroute incoming APM data based on the service.environment field, redirecting events to the correct namespace.
Sounds promising, but there’s a catch: the service.environment field is controlled by the APM Agent. That means an agent could spoof its environment and send data to any namespace. Again, this violates our core requirement – only authorized agents should be able to write to a given namespace.
So this option was also discarded.
Our Solution: Rerouting with Authorization
Inspired by the rerouting concept, we added an authorization layer to make it secure.
Here’s how it works:
- Secret Tokens: Each APM Agent is assigned a unique secret token. This token is sent along with the APM events.
- Token-Namespace Mapping: We store a mapping of tokens to namespaces in a dedicated Elasticsearch index.
- Ingest Pipeline with Enrich Processor: When data arrives, an Enrich processor looks up the token and adds the corresponding namespace to the event.
- Reroute Processor: Finally, the data is rerouted to the correct namespace based on the enriched field.
This approach ensures that only agents with valid tokens can send data to their assigned namespace, meeting our segregation requirements.
Lessons Learned and What’s Next
While our solution works well, it’s a custom integration that we need to maintain. It relies on publicly available Elasticsearch APIs, but we still have to monitor for breaking changes in future Elastic releases.
We’re keeping a close eye on Elastic’s roadmap, hoping for native support that could simplify or even replace our custom setup.
Data segregation in Elastic APM isn’t always straightforward, especially in complex multi-tenant environments. But with a bit of effort you can build secure and scalable solutions that meet your needs.
These Solutions are Engineered by Humans
Are you passionate about performance metrics or other modern IT challenges? Do you have the experience to drive solutions like the one above? Our customers often present us with problems that need customized solutions. In fact, we’re currently hiring for roles just like this as well as other roles here at Würth Phoenix.