30. 06. 2026
APM, DevOps, Kubernetes

30. 06. 2026
Davide Sbetti
AI, Artificial Intelligence, Kubernetes
Load balancing requests to LLMs in Kubernetes: a KV-cache approach with llm-d!
Hi everyone 😃
Today I would like to walk you through some experiments we made when it comes to load balancing requests to LLMs in Kubernetes. Let’s dive deep into it!
Why deploying LLMs in Kubernetes?
Well, Kubernets has now established itself as a leading technology when it comes to workloads orchestration and, with time, the support to accelerators such as GPUs increased, making it now easier to run workloads which can exploit the large parallelism those accelerators provide.
Furthermore, many projects developed to efficiently serve LLMs are provided also in the form of containers, ensuring so an effort-less experience when it comes to their deployments. Some examples include, but are not limited to:
- vLLM: one of the most famous inference engine, given the really good performance, which provides an official Helm Chart
- llama.cpp: the famous engine written in C/C++ with support for many accelerator combinations and also plain CPUs, which offers many documented docker images
- Huggingface: the well-know platform which serves as repositories for models, challenges and recipes, offers many pre-built images for various purposes, such as inference or training
But these are probably not the main reasons to bring Kubernetes in the loop when it comes to LLM serving. Because, actually, one of the main advantages that Kubernetes-like environment bring, is the mentality to deploy workloads in a GitOps way, which ensures our application is consistent with its definition, allowing to also re-deploy it on a different machine or in case a re-installation is needed.
A Kube native approach: Kubeflow
In our case, we decided to try Kubeflow, a project aimed at providing users with separate Kubernetes namespaces where their workloads can run, with support to accelerators and a modular approach which allows the operator to decide which Kubeflow components to deploy, skipping for example some components which are not needed in case you are not training your own models.
We deployed it using the official manifest but with a little trick, namely updating KServe, the component we can actually recognize as a full-fledge model serving platform, to version 0.17, which was not the default one at the time in Kubeflow.
Why 0.17? It all comes down to… llm-d!
Serving a model with KServe and llm-d
Okay, when it comes to applications and serving requests efficiently, one of the main concept adopted regardless the type of application and architecture is having a cache for all what is possible, trying to re-use it and maximize the number of cache hits. It turns out, this can play a role also when it comes to LLMs, but to understand how, we need to explore a bit how the decode phase in modern LLMs works!
But first, how does an LLM actually generate text? 2 minutes recap!
Generating text in an LLM works roughly like this:
- The input — which could be just a system prompt, or a full conversation — is broken into tokens by a tokenizer.
- Each token is projected, via weights learned during training, into a key and a value vector: the key represents what kind of information the token carries, the value represents the actual content of that information.
- The last token also produces a query vector. This query is compared (via dot product) against every key vector in the sequence, producing a score for each token. These scores are normalized into attention weights, which are used to combine the value vectors into a single output — effectively, “how much should I focus on each previous token right now?”
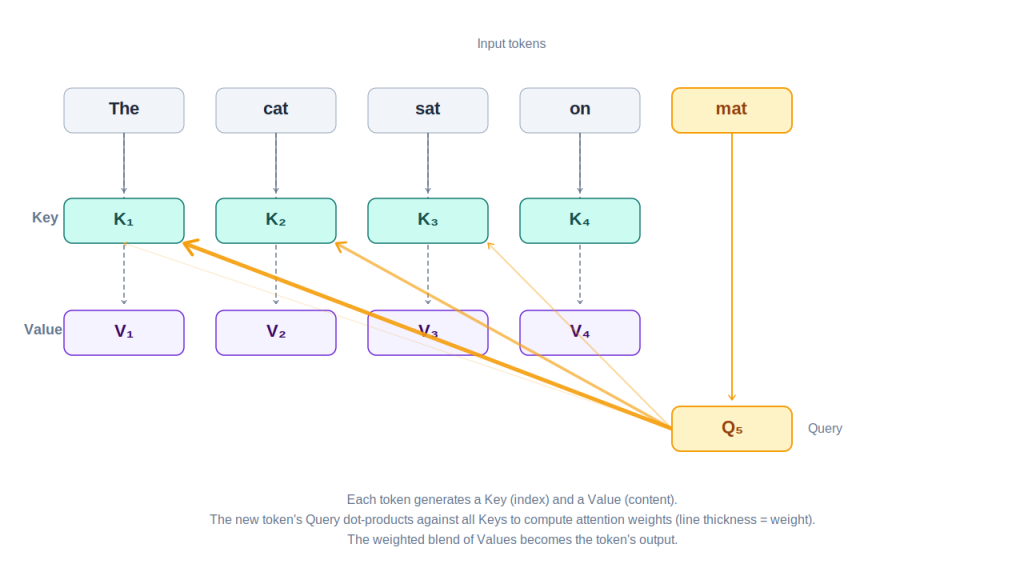
This is what an attention layer does. LLMs stack many of these layers, each followed by a small feed-forward network, refining the representation step by step. After the final layer, the result is projected onto the vocabulary to get a probability distribution over possible next tokens — one of which is sampled (or picked) as the output.
That new token gets appended to the sequence, and the whole process repeats — one token at a time — until a special end-of-sequence token is produced.
Given this, where could we fit an optimization under the form of a cache? Well, keys and values computed for the sequence until a certain step, can be re-used also in the computation of the next step, without the need to re-compute them!
This is exactly the concept behind the KV-Cache, which aims at re-using those already computed values.
Where llm-d comes into play
Let’s imagine we would like to deploy two instances of a model running on two different GPUs, how can we do this? Until the latest versions, KServe offered the InferenceService, which allowed to easily serve an ML model, not only limited to an LLM.
For example, to serve Qwen 2.5 on our two GPUs, we could have done something similar to this:
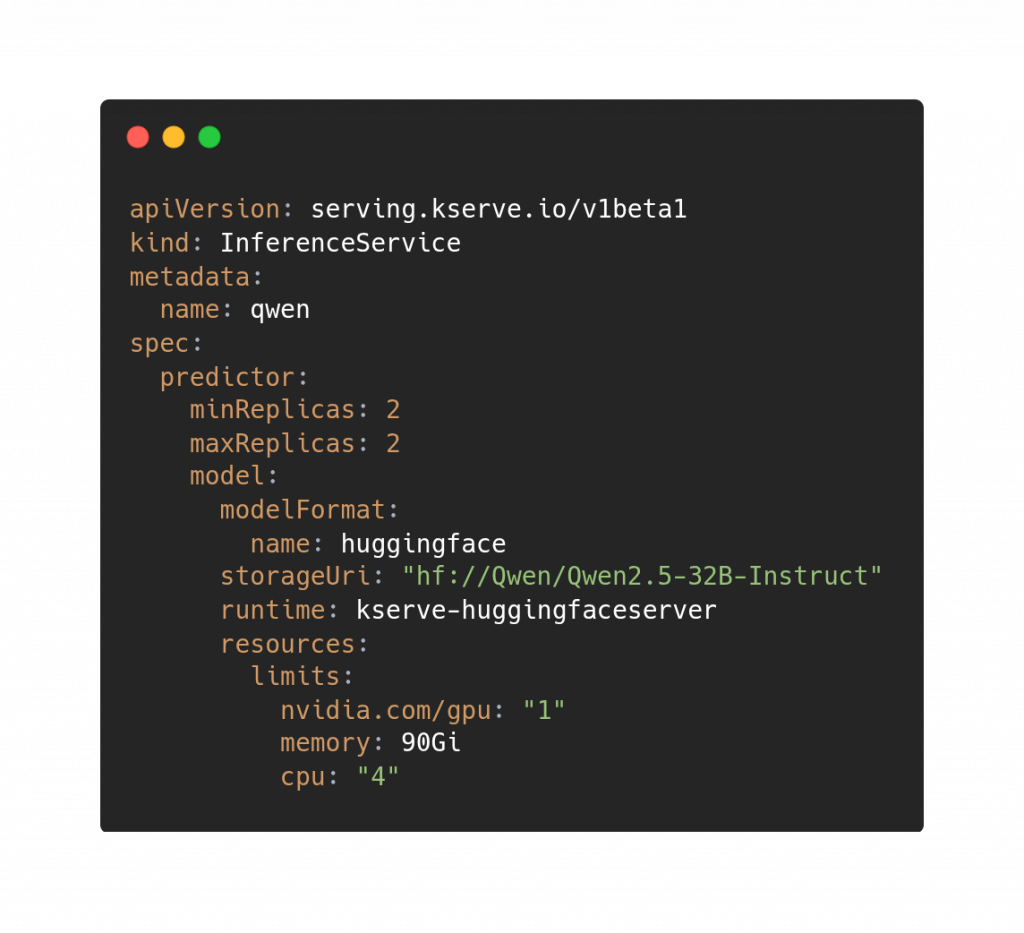
Given that we have two instances, we could load balance users’ requests among the two instances using some standard techniques such as round robin or using metrics such as the load. However, this would not allow us to really exploit, at this stage, the concept of the KV cache we just saw. That’s why, in recent versions, KServe started offering also a more specialized LLMInferenceService, which among the other features, integrates llm-d, which provides also a KV Cache aware router (both approximated or precise, exploiting for example vLLM metrics pushed through ZeroMQ).
We could for example design the following configuration for the EndpointPicker, namely the llm-d component designed to choose among the available instances (endpoints), to use different metrics with different weights, including the precise prefix cache scorer, to maximize the hits, in this case also in an extreme way 😃
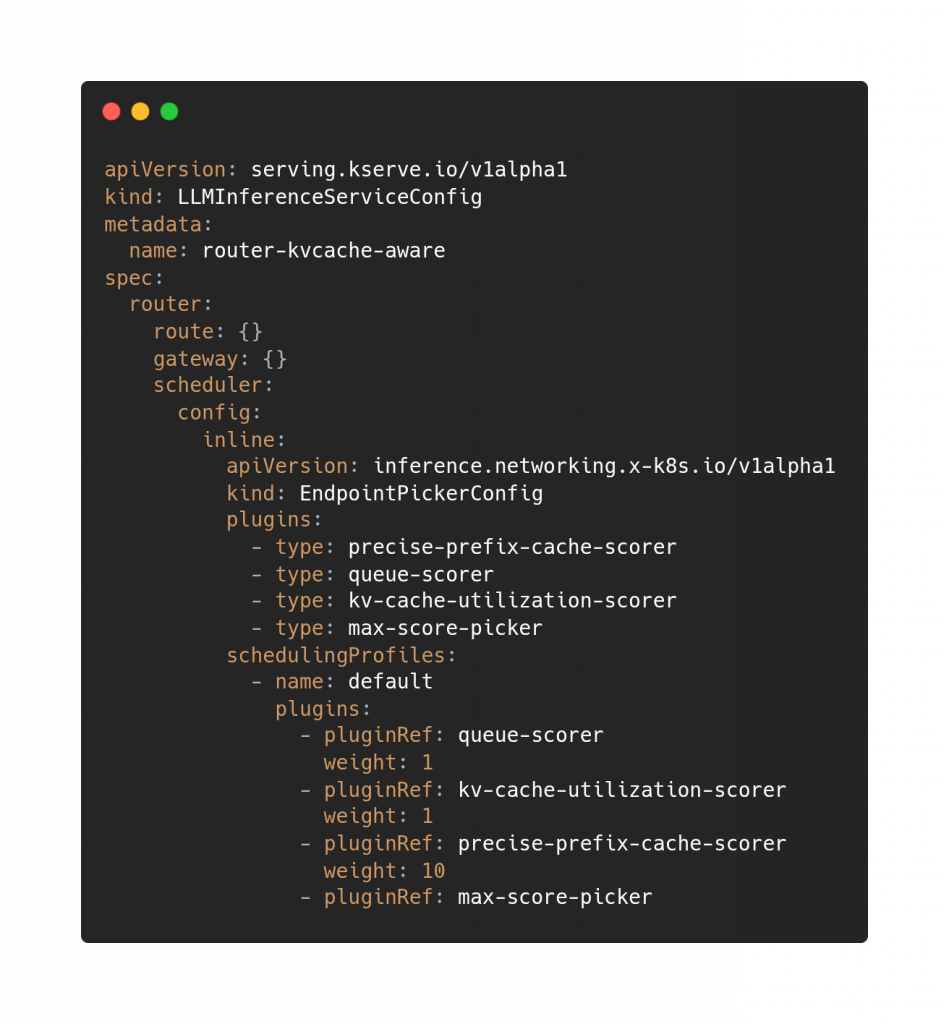
Given that we are using the precise prefix cache we need then to configure our inference runtime, such as vllm, to pass the information of the cache content back to the EndpointPicker, to make it able to take great routing decisions!
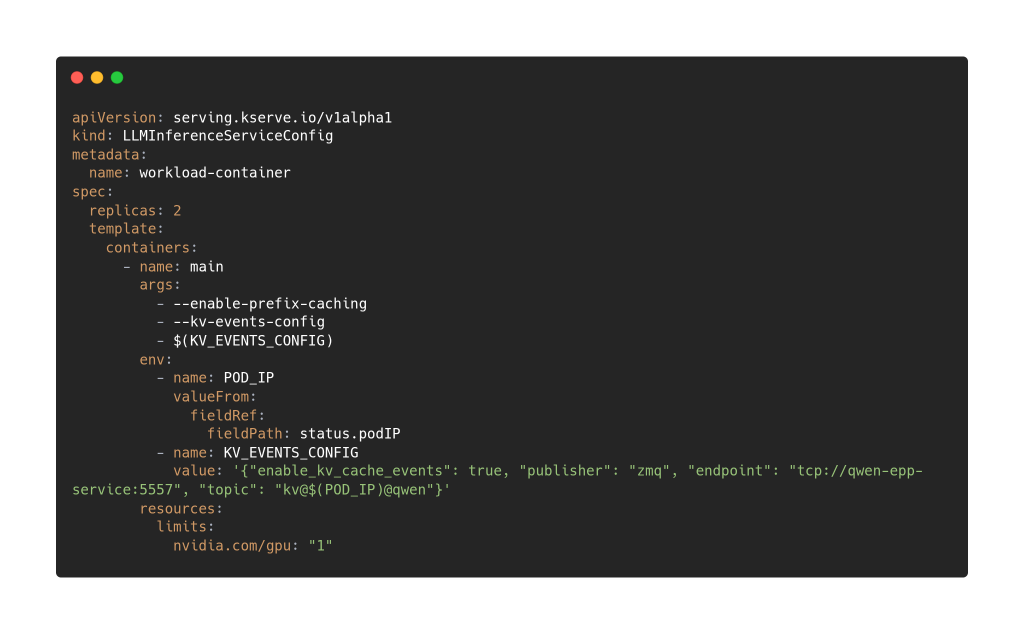
And in this way we are able to serve two instances of a model and have a service able to route requests based also on the content of the KV Cache, to maximize performances and the reduce the time to the first token!
Conclusions
Today we saw some of the benefits of using Kubernetes also for our ML workflows and some interesting tools to be able to efficiently and easily serve LLMs, with an eye on the KV-Cache aware routing!
See you soon 😉
Davide Sbetti
Hi! I'm Davide and I'm a Software Developer with the R&D Team in the "IT System & Service Management Solutions" group here at Würth IT Italy. IT has been a passion for me ever since I was a child, and so the direction of my studies was...never in any doubt! Lately, my interests have focused in particular on data science techniques and the training of machine learning models.
Author
Latest posts by Davide Sbetti
30. 03. 2026
APM, Log Management, Log-SIEM, NetEye
Sending OTel Data to Elasticsearch: Tenant Segregation through OAuth