





30. 06. 2025
DevOps, Kubernetes

A simple reverse proxy might turn out dangerous
Sometimes we inadvertently make assumptions that undermine our infrastructure security. In today’s article I want to share with you one of the most common mistakes that are done when setting up a reverse proxy. As always, real world use cases are the best ones to learn from.
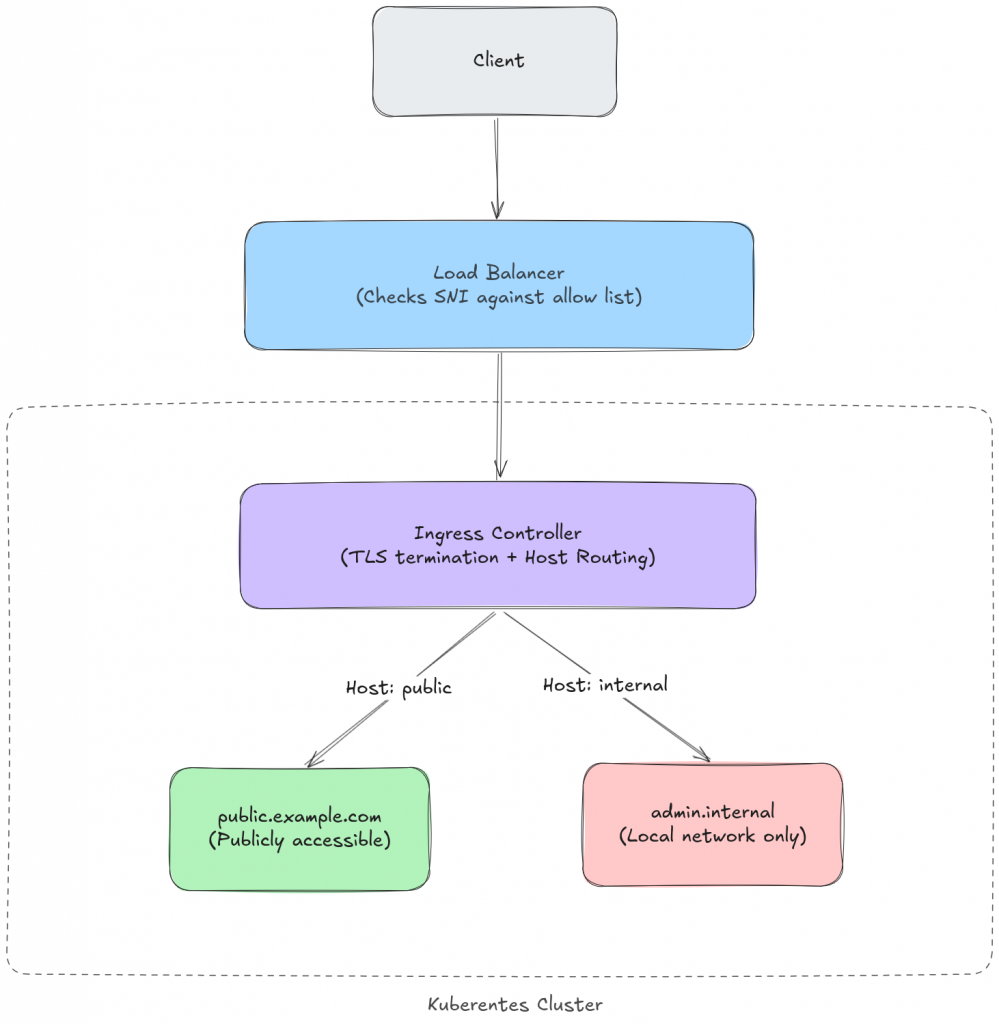
Let’s assume we have a kubernetes cluster on which several services are hosted. Some of which should be publicly accessible, and some others should be available to the local network.
We configure the load balancer to block traffic if the source ip is public and the domain is not in the publicly accessible list.
This architecture is completely legit, though, it might turn out flawed depending on where the TLS termination is performed.
A quick refresher on SNI
Before we dig into the flaw, let’s take a step back and talk about SNI (Server Name Indication). If you already know how it works, feel free to skip ahead.
When a client opens a TLS connection, the very first thing that happens is the TLS handshake. During this handshake the client sends a ClientHello message, which is basically a “hey, I want to talk securely” kind of message. The thing is, the server might be hosting multiple domains behind the same IP address. So how does it know which certificate to present?
That’s where SNI comes in. The client includes the hostname it wants to reach as part of the ClientHello, in a field called server_name. This way the server can pick the right certificate before the encrypted channel is even established.
Here’s the important bit: the SNI is sent in plaintext. It has to be, because at this point in the handshake there’s no encryption yet: we’re still negotiating it. This means that anyone sitting between the client and the server can read the SNI without any effort. And that’s exactly what our load balancer does: it peeks at the SNI to figure out which domain the client is trying to reach.
Now, the SNI is purely a TLS-level concept. It exists to help with certificate selection, and nothing else. It has absolutely nothing to do with HTTP. The HTTP layer has its own way of telling the server which host it wants: the Host header. And these two values? They don’t really talk to each other.
The attack
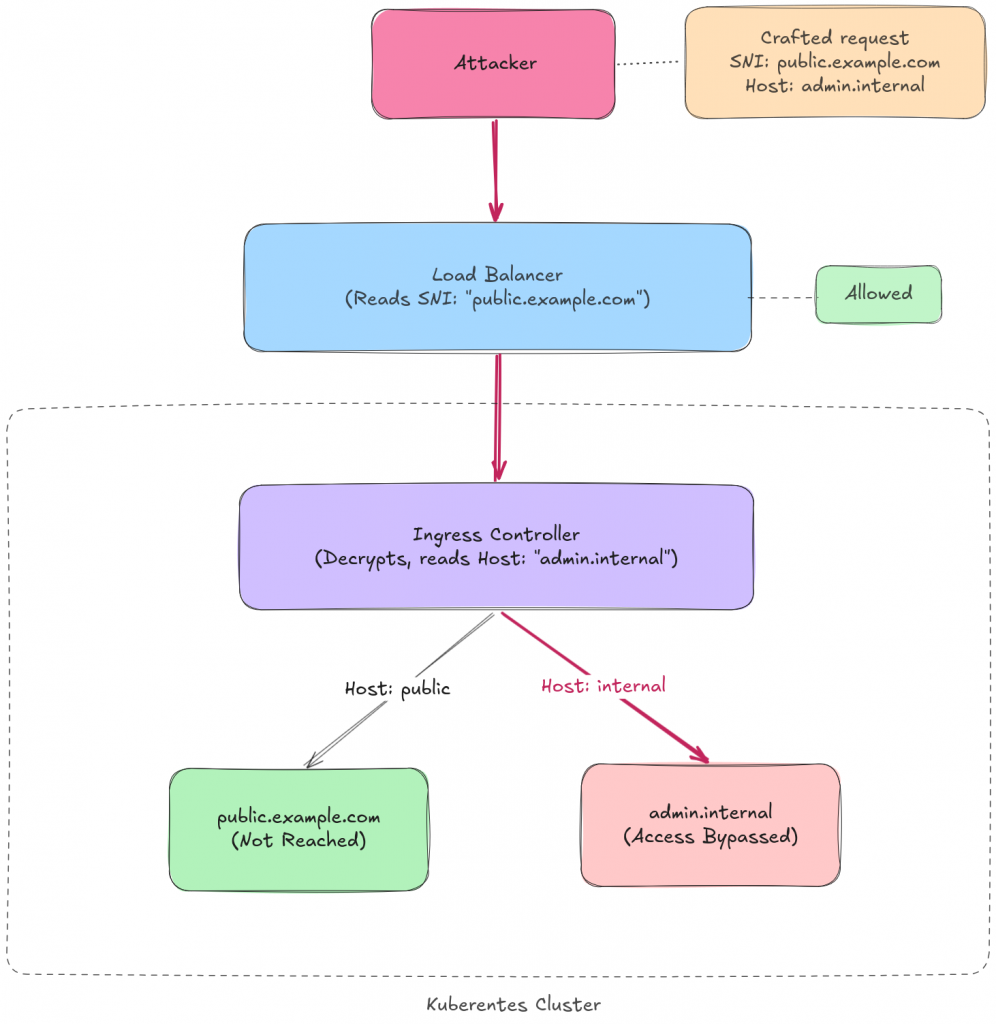
An attacker can craft a request where the SNI is set to a publicly accessible domain, say public.example.com, while the HTTP Host header points to an internal service, say admin.internal.example.com.
The load balancer sees the SNI, checks it against the allow list, and lets the traffic through. The TLS handshake completes successfully because the certificate covers the public domain: and that’s all that matters at this stage. The certificate is validated against the SNI, not against the Host header. The Host header doesn’t even exist yet, it’s buried inside the encrypted HTTP payload. So as far as TLS is concerned, everything checks out.
Then the reverse proxy decrypts the traffic, reads the Host header, and happily routes the request to the internal service.
The attacker just bypassed the access control entirely.
In practice, this can be done with a simple curl command:
curl --resolve public.example.com:443:<LOAD_BALANCER_IP> \
-H "Host: admin.internal.example.com" \
https://public.example.com/
Or, depending on the TLS setup, by directly setting the SNI independently from the Host:
curl --connect-to admin.internal.example.com:443:public.example.com:443 \
https://admin.internal.example.com/
The key point is that the attacker only needs the TLS handshake to succeed with a valid SNI.
What happens after decryption is a different story: one that the load balancer has no visibility into.
Why this happens
The root cause is pretty straightforward once you see it: TLS and HTTP are two different protocols, designed independently, and neither one cares about being consistent with the other. The SNI exists to help the server select the right certificate during the handshake. The Host header exists to help the HTTP layer route the request. They serve different purposes and there’s no built-in mechanism that ties them together.
When the access control decision is made at the TLS layer but the routing decision is made at the HTTP layer, you’re effectively relying on the assumption that clients will always set both values to the same domain. A legitimate browser will. An attacker won’t.
If you think about it, it’s a textbook confused deputy problem. The reverse proxy trusts that the request has already been authorized by the load balancer. The load balancer trusts that the SNI accurately represents where the traffic is headed. Neither assumption holds when an adversary is in the picture.
Mitigation
There are a few ways to address this, and the right one depends on your architecture and what trade-offs you’re willing to accept.
Terminate TLS at the load balancer. This is the most straightforward fix. If the load balancer performs TLS termination itself, it can inspect both the SNI and the Host header before making the routing decision. The cross-layer gap just disappears. The downside? You lose end-to-end encryption between the load balancer and the backend. You can bring it back with mTLS internally, but that means managing more certificates and dealing with some extra latency. If your threat model doesn’t require encryption within the cluster, though, this is probably the simplest path.
Enforce SNI-Host consistency. Some reverse proxies and ingress controllers can be configured to reject requests where the Host header doesn’t match the SNI. This is the most surgical fix: you keep TLS termination at the backend, and you just add a check that closes the gap. Worth noting that not every ingress controller supports this out of the box, so check the docs for yours.
Network-level segmentation. Instead of relying on domain-based filtering at the load balancer, place internal services on a separate network that is genuinely unreachable from the public internet. If the traffic can’t physically reach the internal service, the Host header trick becomes irrelevant. This is the defense-in-depth approach: even if someone finds another way to mess with the routing, the network topology has your back.
Dedicated ingress for internal services. Use a different ingress controller (or a different listener) for internal services, one that is not exposed through the public load balancer at all. This way, even if an attacker manages to sneak a crafted Host header through, there is no ingress rule that would match it on the public-facing side.
Takeaway
The lesson here is simple but easy to forget: when two protocol layers are involved in a security decision, you have to make sure they agree. If access control happens at one layer and routing at another, you’ve created a gap that an attacker can walk right through.
Every time you set up a reverse proxy, ask yourself: who is making the decision, and based on what information? If the answer involves two different components looking at two different values, you probably have a problem.
Interested in further readings? You might find this article useful!
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Programming is at the heart of how we develop customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.
Author
Latest posts by Alessandro Taufer
31. 12. 2025
Development, DevOps
What Tests Can Tell You About Your Codebase
19. 09. 2025
Development, DevOps
How to Debug Your Kernel Calls