





02. 04. 2026
NetEye, Unified Monitoring

29. 12. 2022
Rocco Pezzani
NetEye
Finding Subtle Changes in your NetEye 4 Monitoring during Critical Activities
Rules and standards are important. In a world based on collaboration, following a well defined behavior is key for avoiding errors based on some sort of misunderstanding. This is also true for the world of information technology: someone releases software that is incomplete by design, and then leaves the completion of it to the people who need to use it. To do so, that someone prepares a draft of the requirements about how to continue the work and publishes it, sure that everyone will then read it and stick to it.
I can already see some of you laughing, while others shake their head in complete disapproval. But please stop right there and think for a moment. What if:
- The incomplete software is Icinga 2
- The software that completes Icinga 2 is a Monitoring Plugin
- The draft is the Nagios Plugins Development Guidelines
Does that make sense? I think it does. It definitely does because Icinga 2 simply launches a third-party program (i.e., one of the Monitoring Plugins) without even knowing what it does, and even so it tries to parse the output from that program. Icinga 2 is really “incomplete”, because it requires another program in order to reach its main goal: monitoring a device, whatever it may be.
This is the power of Icinga 2, and is what makes NetEye 4 so flexible about monitoring: the use of an extremely specialized piece of software written by a third-party to monitor almost any kind of object. And if this software is not present, we can build it in a relatively easy way. How? By using our own preferred programming language and following the Nagios Plugins Development Guidelines. And this is where problems begin to crop up.
It’s really difficult for people to follow standards made by others before them, and following the Nagios Plugin Development Guidelines is no exception. As an example, let’s talk about the definition of the UNKNOWN State:
Invalid command line arguments were supplied to the plugin or low-level failures internal to the plugin (such as unable to fork, or open a TCP socket) that prevent it from performing the specified operation. Higher-level errors (such as name resolution errors, socket timeouts, etc) are outside of the control of plugins and should generally NOT be reported as UNKNOWN states.
From Nagios Plugins Development Guidelines
Let’s make a deliberate error: try to use the check_ping plugin to monitor the state of a non-existent FQDN.

As you can see, the Plugin returns the value 3, which is the return code of the UNKNOWN state. But this is clearly wrong: the UNKNOWN state definition states “Higher-level errors (such as name resolution errors, socket timeouts, etc) … should generally NOT be reported as UNKNOWN states”. Okay, it says “generally”, so perhaps this can be considered as a borderline case, but consider this one:
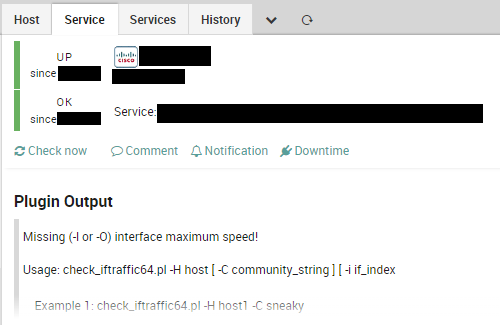
As much as it pains me to say it, one of the most widely used plugins for NIC monitoring, check_iftraffic64 (as well as check_iftraffic) returns OK instead of UNKNOWN in the case of a missing argument. Also, our recent experience in updating NetEye from version 4.22 to version 4.23 tells us something about monitoring plugins: that before the upgrade a plugin returned CRITICAL because the monitored object was really not working, but that afterwards the upgrade returned CRITICAL because some OS Library was missing. So where is the UNKNOWN state when we need it?
This is not because of poor programming. Okay, it certainly is, but the main point is somewhat different: sometimes errors happen outside of our control. We must find a way to find these errors, especially during upgrades or other critical activities. And therefore we need a way to see what has changed in NetEye 4 Monitoring after completing a critical activity.
With the help of our precious consultant Tommaso Fontana, we developed a little tool with a simple objective: compare the state of NetEye Monitoring at two different times and highlight the differences. This tool, named state_diff, operates by talking directly to the Icinga 2 API to get a picture of the current state of the monitored objects; it then compares it with a snapshot taken previously to identify what has changed. Knowing that a monitored object can be a Host Object or a Service Object, it follows these steps:
- Identify added or removed monitored objects and reports them
- Identify all monitored objects that have changed their state, and report them
- Among all those monitored objects that maintain their state, identify the ones with differences in the Plugin Output and report them
As you can see, it doesn’t just perform a simple diff. It proceeds by a series of steps: first, identifying new or removed entries (these are worthy of just a brief mention). The second step is to identify major changes, namely state changes. A state change can be due to either an error in the monitored object or an error in monitoring itself, so it’s worth investigation. The third and last step is the most critical. As we discussed previously, the most subtle scenario is when the plugin reports the same state for different purposes, for example an Internal Error.
Given the assumption that a change in the plugin output might be due to an internal error, state_diff identifies these changes and reports them. Of course, some changes might be legitimate: for instance, the plugin output of check_ping varies based on the packet loss and RTA it identifies. So, how does state_diff handle this kind of situation?
state_diff is provided with a set of output patterns (does regular expressions sound better?) that it can recognize: if both before and after the activity the plugin output matches at least one of these patterns, its monitored object is not reported. Finally, state_diff produces a report in Markdown or JSON format: the first one for human beings, and the second for a script to post-process when required.
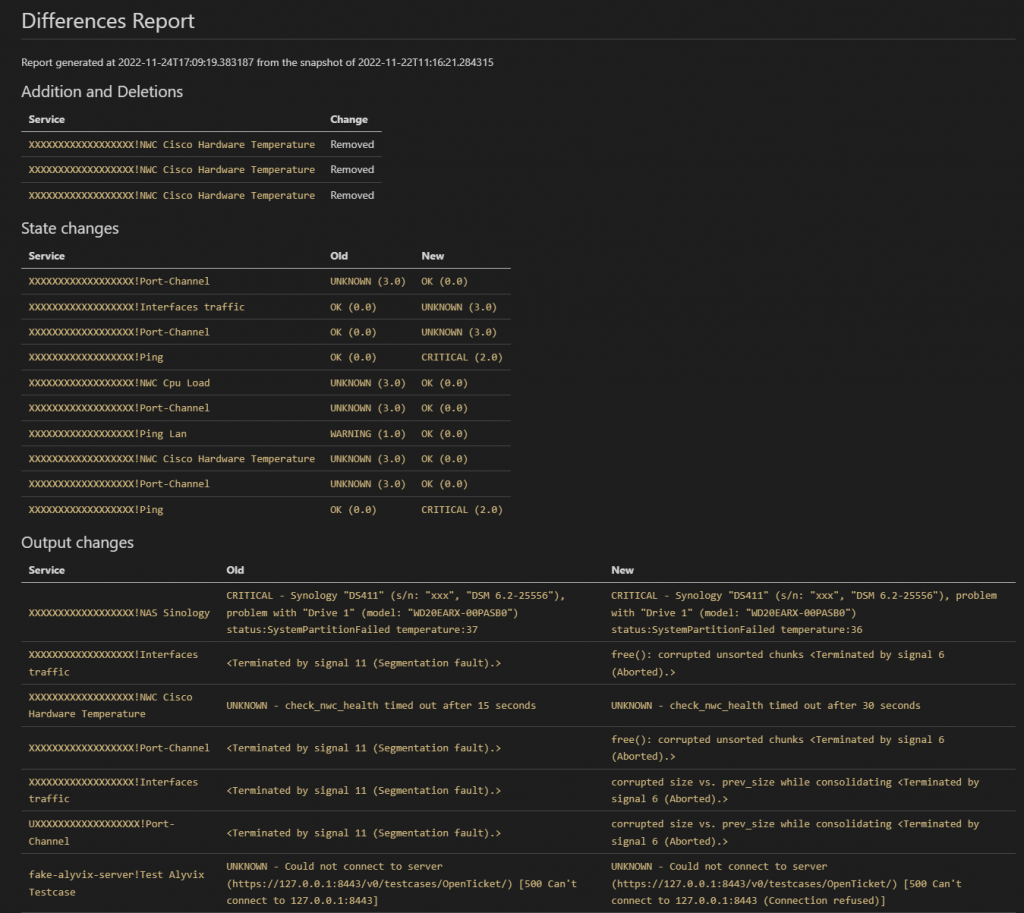
So you can use state_diff to get a snapshot of your NetEye 4 monitoring status before beginning a critical activity, then compare its status either during the activity itself or at the end of it, in order to understand what’s really going on in your NetEye 4 environment.
This tool is not currently shipped with NetEye 4 nor with NetEye Extension Packs, therefore if you’d like to use it, ask a NetEye 4 consultant to install it on your system.
These Solutions are Engineered by Humans
Did you like this article? Does it reflect your skills? We often get interesting questions straight from our customers who need customized solutions. In fact, we’re currently hiring for roles just like this and other roles here at Würth Phoenix.
Author
Latest posts by Rocco Pezzani
18. 03. 2025
Icinga Web 2, ITOA, NetEye, UI, Unified Monitoring
A First Step towards Multitenancy in Icinga 2
31. 12. 2024
Business Service Monitoring, ITOA, NetEye, SLM, Unified Monitoring
Display a Service’s Availability with ITOA
30. 11. 2024
Business Service Monitoring, NetEye, Unified Monitoring
The Story of a Strange Business Process