





27. 03. 2026
Automation, Development, DevOps, NetEye

30. 12. 2024
Alessandro Taufer
DevOps, Log-SIEM
Configure Kubernetes Index Lifecycle Policies in Elastic Stack
If you’re monitoring an OpenShift or a Kubernetes cluster with Elastic Stack, you might’ve noticed that the Kubernetes integration uses the default Index Lifecycle Policy. It means that those logs and metrics have an unlimited retention. If the volume of logs is high – and for Kubernetes clusters it usually is – it won’t be sustainable.
Unfortunately due to the design of the integration, configuring them is a bit trickier than it might seem.
Where the Problem Lies
A quick search in the data streams section will reveal that the integration by default uses 22 data streams.
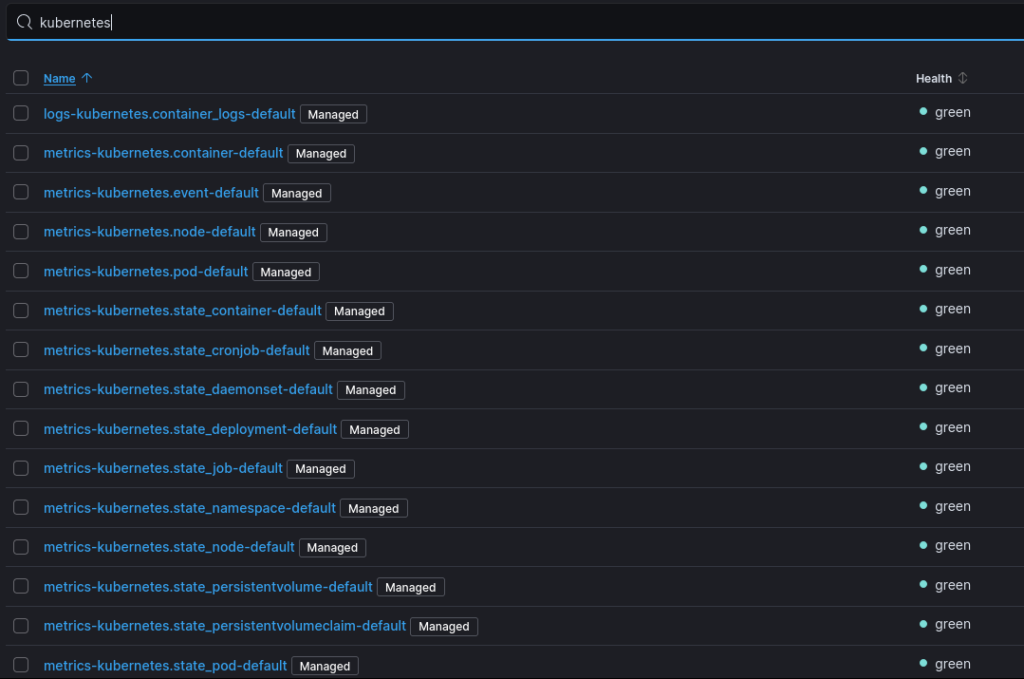
Configuring them manually is something that should absolutely be avoided for multiple reasons:
- It’s error prone
- That slow, manual process must be repeated every time you edit them
- None of your colleagues can be sure how they are configured without checking each one of them
Luckily, I’ve already created a small script that you can adapt to your use cases. It performs two main operations:
- Edits the custom component template
- Forces the rollover and removes legacy indexes
Editing the Custom Component Template
The first step of the procedure consists of assigning the ILP to each data stream. The right way to do it is to edit the custom component template, which will prevent future updates of the integration from resetting back to the default setting:
# The name of the ILP you want to use
index_lifecycle_policy_name="kubernetes-metrics"
# Authentication credentials of elastic
ELASTICSEARCH_MONITORING_CERTS_PATH="/neteye/local/elasticsearch/conf/certs"
elastic_curl="/usr/bin/curl -sS -E $ELASTICSEARCH_MONITORING_CERTS_PATH/admin.crt.pem --key $ELASTICSEARCH_MONITORING_CERTS_PATH/private/admin.key.pem https://elasticsearch.neteyelocal:9200"
# Retrieve the list of custom component templates of the kubernetes integration
kube_component_templates=$($elastic_curl/_component_template/*kubernetes*@custom | jq -r '.component_templates[].name')
for component_template in $kube_component_templates; do
echo "Configuring component template: $component_template"
# Set the ILP for the given custom component template
$elastic_curl/_component_template/$component_template \
-H 'Content-Type: application/json' \
-d "{
\"template\": {
\"settings\": {
\"index.lifecycle.name\": \"${index_lifecycle_policy_name}\"
}
}
}"
done
Force the Rollover of the Indexes
Even if we assigned the Index Lifecycle Policy to the data streams, it won’t be used by the indexes that already exist. You’ll have to force a rollover to bring them into use (close the index and create a new one).
# Retrieve the list of datastreams of the kubernetes integration
kube_data_streams=$($elastic_curl/_data_stream/*kubernetes* | jq -r '.data_streams[].name')
for kube_data_stream in $kube_data_streams; do
echo "Data stream: $kube_data_stream"
# Force the rollover of the index
$elastic_curl/$kube_data_stream/_rollover -X POST
done(Optional) Remove the Legacy Indexes
When forcing a rollover of indexes, be aware that the old indexes remain in the system and continue to follow their original lifecycle policies, preventing automatic deletion. After confirming that these legacy indexes are no longer needed for your operations, you can proceed with a bulk deletion to reclaim storage space.
# Remove legacy indexes
for kube_data_stream in $kube_data_streams; do
# Retrieve the list of indexes associated with the data stream that have an ILM policy different from the one we want to set
indexes=$($elastic_curl/_data_stream/${kube_data_stream} -H 'Content-Type: application/json' | jq -r ".data_streams[0].indices[] | select(.ilm_policy != \"$index_lifecycle_policy_name\") | .index_name")
# Delete each index
for index in $indexes; do
echo "Deleting index: $index"
$elastic_curl/$index -X DELETE -H 'Content-Type: application/json'
done
doneConclusion
Exercise caution when tweaking this code to fit your needs. It’s quite flexible, but these changes can lead to unexpected results if not handled carefully. You can find the complete version of the code here
Interested in further reading about monitoring Kubernetes? You might find this article useful!
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Programming is at the heart of how we develop customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.
Author
Latest posts by Alessandro Taufer
31. 03. 2026
DevOps, Kubernetes
Abusing Trust Boundaries between TLS and HTTP
31. 12. 2025
Development, DevOps
What Tests Can Tell You About Your Codebase
19. 09. 2025
Development, DevOps
How to Debug Your Kernel Calls