





11. 04. 2024
Business Service Monitoring, NetEye, SLM


Der Microsoft Exchange Server ist eines der weitverbreitetsten Systeme für das Versenden von Geschäftsemails, aber leider ist es manchmal etwas schwierig ihn zu überwachen. Oft beschränken sich daher die implementierten Kontrollen auf die Überwachung der Verfügbarkeit des Servers im Netzwerk.
Mit der Version 2013 ist jedoch ein großer Schritt nach vorne gelungen: Microsoft stellt eine Serie von URLs zur Verfügung (Healthcheck URL), um die tatsächliche Verfügbarkeit der Dienste, die den Kunden bereitgestellt werden, zu überwachen.
Diese Healthcheck URLs haben alle eine ähnliche Struktur:
https://<External FQDN>/<protocol>/healthcheck.htm
Die Namen der Protokolle werden folgendermaßen übersetzt:
- OWA Outlook Web App
- ECP Exchange Control Panel
- OAB Offline Address Book
- AutoDiscover Autodiscover Prozess
- EWS Exchange Web Services (Mailtips, Free/Busy, Lync clients, Outlook for Mac)
- Microsoft-Server-ActiveSync Exchange ActiveSync
- RPC Outlook Anywhere
- MAPI MAPI/HTTPS (ab Exchange 2013 SP1)
Die regelmäßige Kontrolle dieser URLs bietet also die Möglichkeit das Funktionieren der Module des Servers abzufragen. Leider hilft dieses Vorgehen aber nicht dabei zu verstehen ob Performanceeinbußen vorliegen.
Für eine genauere Kontrolle müssen wir notwendigerweise auf einen, lokal auf dem Exchange Server installierten, Agenten zurückgreifen. Verwenden wir einen Agenten der mit einer bestimmten Frequenz die von Exchange zur Verfügung gestellten Leistungsdaten (die sogenannten Performance Counters) prüft, vermeiden wir eine weitere Belastung des Servers durch zusätzliche Abfragen.
Die Lösung mit NetEye
Für die Überwachung von Exchange in NetEye, verwenden wir die folgenden drei Open Source Lösungen:
- Telegraf, um die Leistungsdaten des Exchange Servers zu sammeln
- InfluxDB, um die Daten abzulegen und zu historisieren
- Grafana, um ein Dashboard für die Darstellung der wichtigsten Informationen zu erstellen
Telegraf ist ein sehr einfacher Agent, der in der Lage ist die Performancedaten die von Exchange ausgegeben werden in bestimmten, konfigurierbaren Abständen (normalerweise 5 Sekunden) auszulesen und diese über das Netzwerk an eine remote InfluxDB Datenbank zu schicken. Der Agent kann auch einen lokalen Buffer unterhalten, um die Daten im Falle temporärer Verbindungsprobleme nicht zu verlieren.
InfluxDB ist eine für das Historisieren von Metriken optimierte Datenbank, die einen schnellen Zugriff auf die Daten in der Analysephase ermöglicht.
Grafana ermöglicht die Erstellung navigierbarer Dashboards, in welchen die Monitoring-Daten visualisiert und für den gewünschten Zeitraum korreliert werden können.
Sowohl InfluxDB als auch Grafana sind bereits seit der Version 3.9 fixer Bestandteil von NetEye.
Welche Daten sollen überwacht werden?
Für das Monitoring eines Exchange-Servers ist es wichtig eine Reihe von Metriken unter Kontrolle zu behalten.
Das Versenden von E-Mails kann durch eine Reihe von Umständen negativ beeinflusst werden. Beispiele hierfür können sein: Vermehrtes Eintreffen von Spam-Mails, ungewöhnliche Aktivitäten der User (z.B. das Versenden der Weihnachtswünsche) oder Verbindungsprobleme mit dem Internet.
Außerdem muss die Latenz der Zugriffe auf die Active Directory geprüft werden, da auch diese Verlangsamungen oder andere Probleme am Exchange Server hervorrufen kann.
Auf User-Seite können die Daten von ActiveSync (typischerweise die Zugriffe über Smartphones), Outlook Web Access (Webmail) und RPC (normalerweise die Outlook-Zugriffe) verfolgt werden.
In Hinblick auf OWA sei erwähnt, dass es in Exchange 2016 Probleme bei der Generierung der Metriken gibt und sie sogar teilweise nicht verfügbar bzw. unzuverlässig sind. Hoffentlich bringt Microsoft das bald in Ordnung. Alternativ kann auf die Analyse der IIS Daten zurückgegriffen werden: .NET und ASP.
Auf Datenbank-Seite ist es wichtig die Frequenz der Generierung der Logfiles auf den Platten unter Kontrolle zu behalten, um Abweichungen und die Anzahl der Sessionen die auf die Datenbanken zugreifen hervorzuheben.
In Zusammenhang mit den Datenbanken steht auch der Exchange-Cache: ein niedriger Korrespondenz-Wert (Hit Count) weißt oft auf ein Karenz-Problem des Speichers hin.
Letztendlich sind da noch die Zugriffe auf die Platten auf denen die Datenbanken angesiedelt sind: im Fall erhöhter Latenz gibt es negative Auswirkungen auf mehreren Ebenen.
Grafana ermöglicht es alle diese Werte auf einem zentralen Dashboard darzustellen und entsprechend Spitzen und Werte außerhalb der Norm anzuzeigen. Die Panels sind dabei immer synchronisiert damit wir eine genaue Übersicht über die unterschiedlichen Objekte, zu den jeweils kritischen Zeitpunkten, erhalten.
Eine Ansicht mit einer sehr weiten Skala zeigt dementsprechend eine sehr generelle Übersicht:
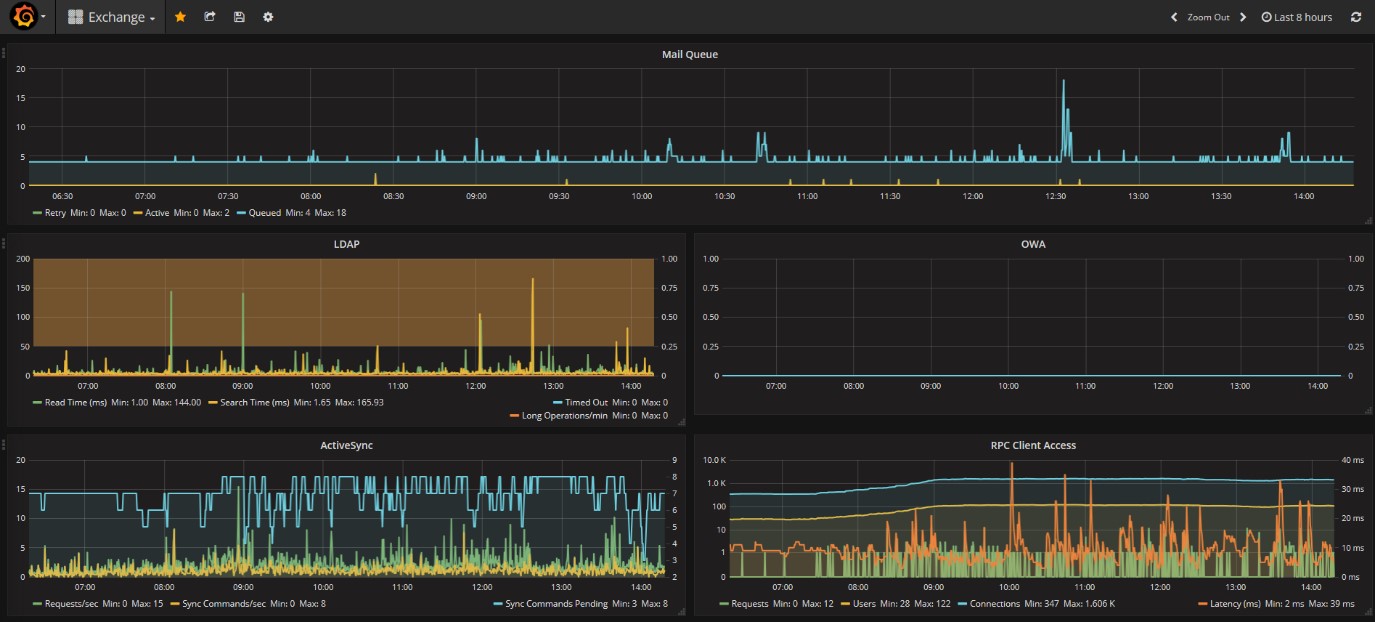
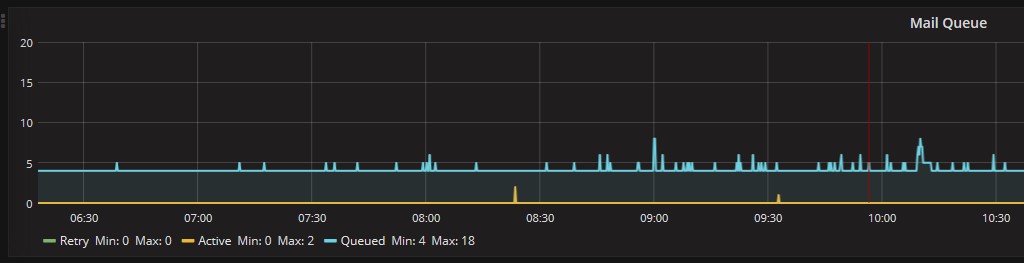
Gehen wir etwas mehr ins Detail (Verkürzen und „strecken“ also den angezeigten Zeitraum), sehen wir, dass die Mail Queues ganz normal aussehen:
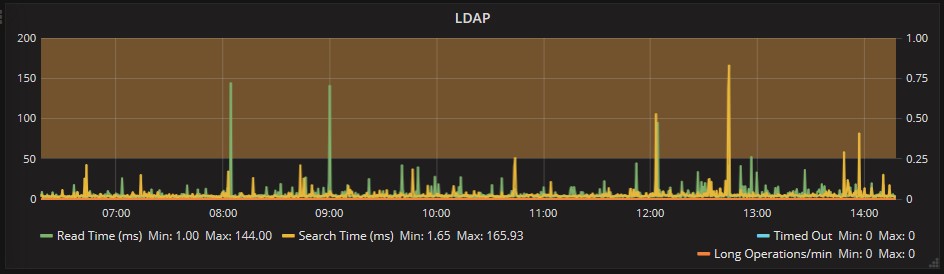
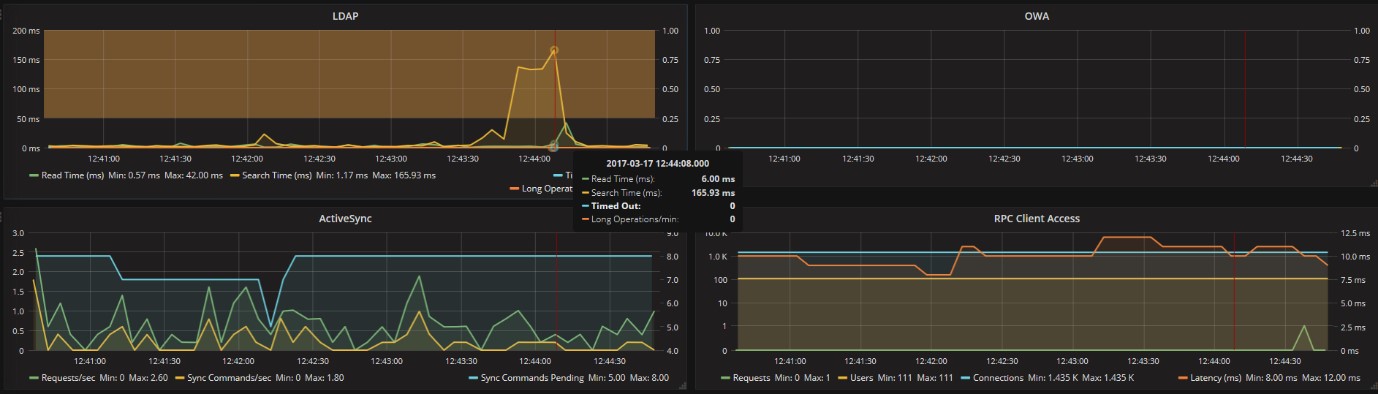
Wir können zusätzlich auch die LDAP Zugriffe auf die Active Directory betrachten. Im untenstehenden Beispiel sehen wir, dass es zu einigen Zeitpunkten die Antworten langsam waren. Allerdings ist auch hier noch nichts kritisches ersichtlich:
Auch auf ActiveSync Seite gibt es im geprüften Zeitraum keine besorgniserregenden Queues:
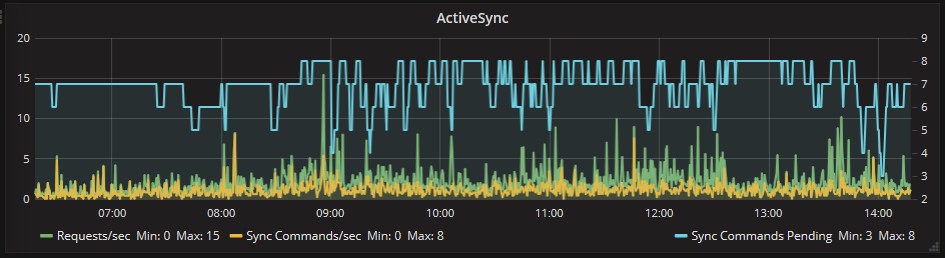
Auch für RPC (Outlook) antwortet der Server korrekt:
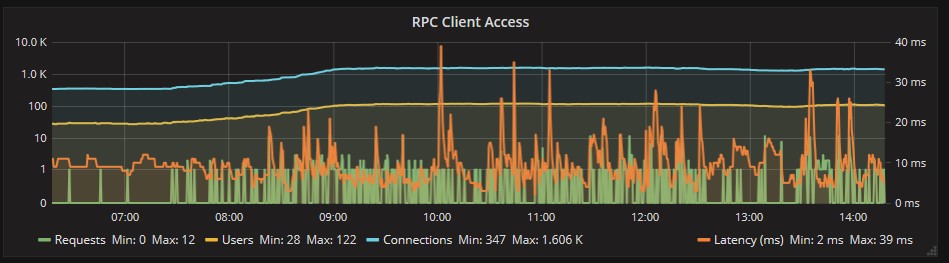
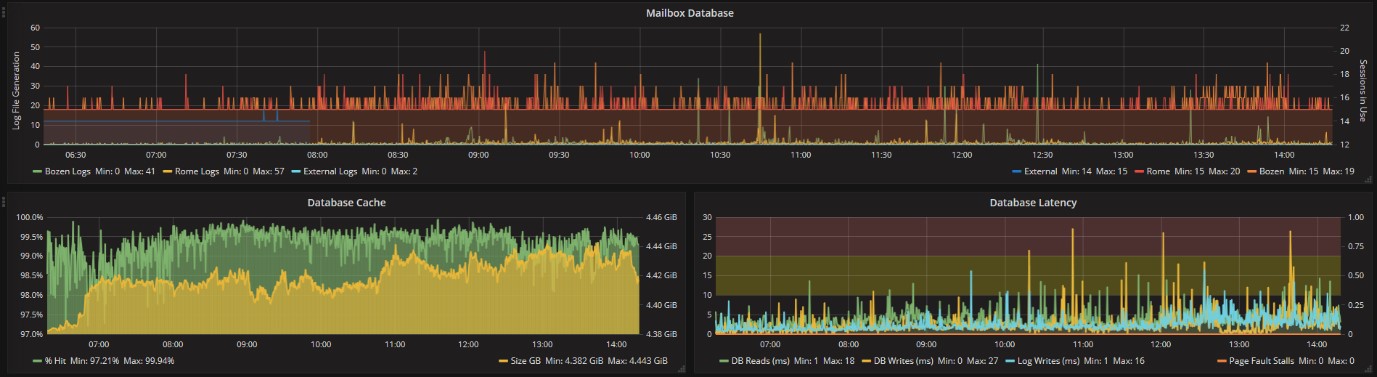
Für die drei Mailbox-Datenbanken in unserem Beispiel, verhält sich die Log-Frequenz ganz normal, ohne auffällige Spitzen:

Der Cache wird vom Exchange Server korrekt genutzt, es gibt keine Probleme mit der RAM:
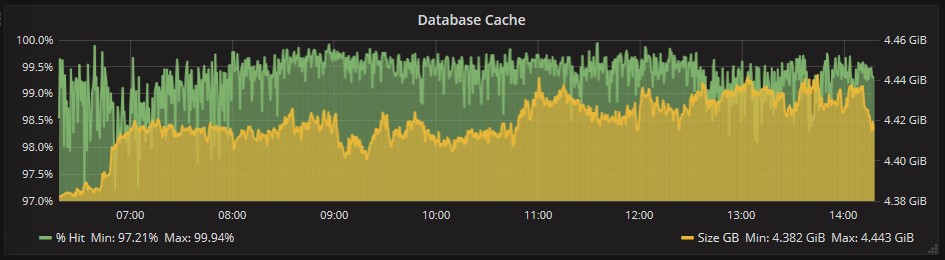
Die einzige Anmerkung müssen wir beim Zugriff auf die Platten machen, wo einige Verlangsamungen zu sehen sind, zum Glück aber nur sporadisch:
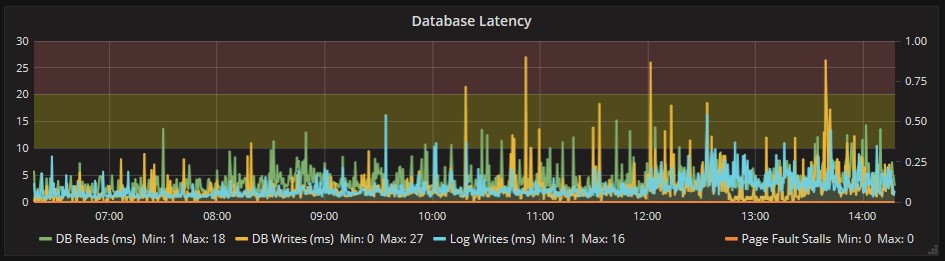
Es liegen keine Blockaden (Stalls) vor. Die Werte die wir trotzdem unter Kontrolle behalten sollten sind jene in Hinblick auf das Lesen der DB von der Platten und das Schreiben der Logs.
Um die Details zu analysieren (zum Beispiel eine der Spitzen der LDAP Zugriffe) kann das angezeigte Zeitintervall verkleinert werden damit erkennbar wird ob ein Problem einer Komponente Service-Einschränkungen verursacht hat oder ob es von unnormalen Auslastungen einer anderen Komponente verursacht wurde.
Fazit
Die Basis-Metriken die ich in diesem Beispiel aufgezeigt habe, sind ein guter Ausgangspunkt um dann je nach Bedarf Weitere auszuwählen die für den Exchange Server überwacht werden sollen.
Dieses Dashboard kann erweitert und personalisiert werden z.B. durch die Integration der Daten des Antispam / Mail Relay.

Alessandro Romboli
Site Reliability Engineer at Würth Phoenix
My name is Alessandro and I joined Würth-Phoenix early in 2013. I have over 20 years of experience in the IT sector: For a long time I've worked for a big Italian bank in a very complex environment, managing the software provisioning for all the branch offices. Then I've worked as a system administrator for an international IT provider supporting several big companies in their infrastructures, providing high availability solutions and disaster recovery implementations. I've joined the VMware virtual infrastructure in early stage, since version 2: it was one of the first productive Server Farms in Italy. I always like to study and compare different technologies: I work with Linux, MAC OSX, Windows and VMWare. Since I joined Würth Phoenix, I could also expand my experience on Firewalls, Storage Area Networks, Local Area Networks, designing and implementing complete solutions for our customers. Primarily, I'm a system administrator and solution designer, certified as VMware VCP6 DCV, Microsoft MCP for Windows Server, Hyper-V and System Center Virtual Machine Manager, SQL Server, SharePoint. Besides computers, I also like photography, sport and trekking in the mountains.
Author
Latest posts by Alessandro Romboli
11. 04. 2024
Business Service Monitoring, NetEye, SLM
SLA Reporting on a Business Process
06. 12. 2023
Business Service Monitoring, NetEye
Monitoring a Business Process
07. 08. 2023
Business Service Monitoring, ITOA, NetEye
From Icinga 2 Monitoring to ITOA
07. 12. 2022
Business Service Monitoring, NetEye, Unified Monitoring
Monitoring Veeam Backup & Replication