03. 06. 2026
SATAYO, SEC4U, Threat Intelligence

09. 06. 2023
Francesco Pavanello
Exposure Assessment, SATAYO, SEC4U, Threat Intelligence
Exposure Assessment: The Best Way to Easily Discover a Target’s Infrastructure
Some time ago we started this series of articles with the aim of technically describing the various objects collected within our Exposure Assessment activity. This is based on SATAYO, our OSINT & Cyber Threat Intelligence platform. Unfortunately, we stopped writing about it for a while; but during this time we’ve continued to develop the platform and it has grown a lot. Therefore, we start here with a brief summary of what an exposure assessment is. Then we’ll go into the details of its early stages which outline a target’s infrastructure.
Exposure Assessment
Using SATAYO we simulate the first phase of an attack as described by Lockheed Martin in its Cyber Kill Chain [Fig. 1]. They call it the Reconnaissance phase, and it consists of gathering as much information as possible about the target. Typically a threat actor invests most of the time necessary to carry out an attack in this phase. In fact, the quality of this phase is what will inexorably determine the success or failure of the intrusion attempt.
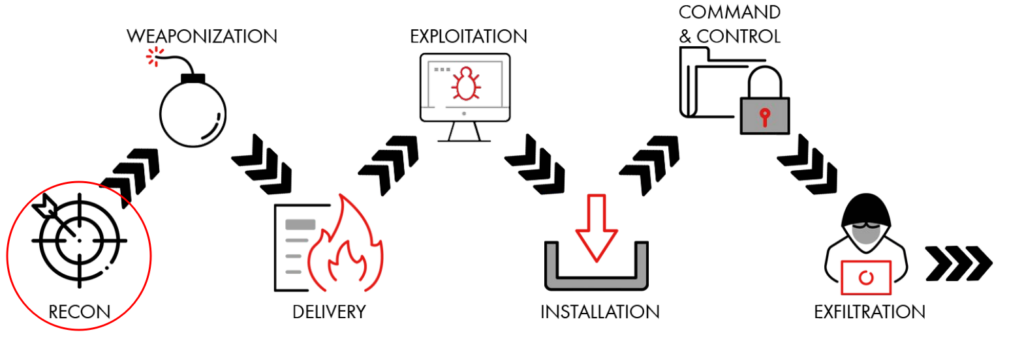
It’s important to carry out the research stealthily, to not trigger any Intrusion Detection System (IDS) the target has that might block the investigation. The best way to do that is using Open Source Intelligence (OSINT) techniques. OSINT is the branch of Intelligence that collects and analyzes information only from publicly available sources, like the internet, newspapers, government public documents, grey literature, radio, and television transmissions. However, SATAYO involves only Internet sources, since the goal is to discover a target’s virtual perimeter.
SATAYO Insights
Speaking of SATAYO investigations, every line of research starts from the target domain [Fig. 2].
Basically, once it receives this information as input, it collects what we can refer to as first level objects or evidence. It’s then possible to go more in depth using this information as new starting points, and so on, making it possible to gain a complete appraisal of the exposure.
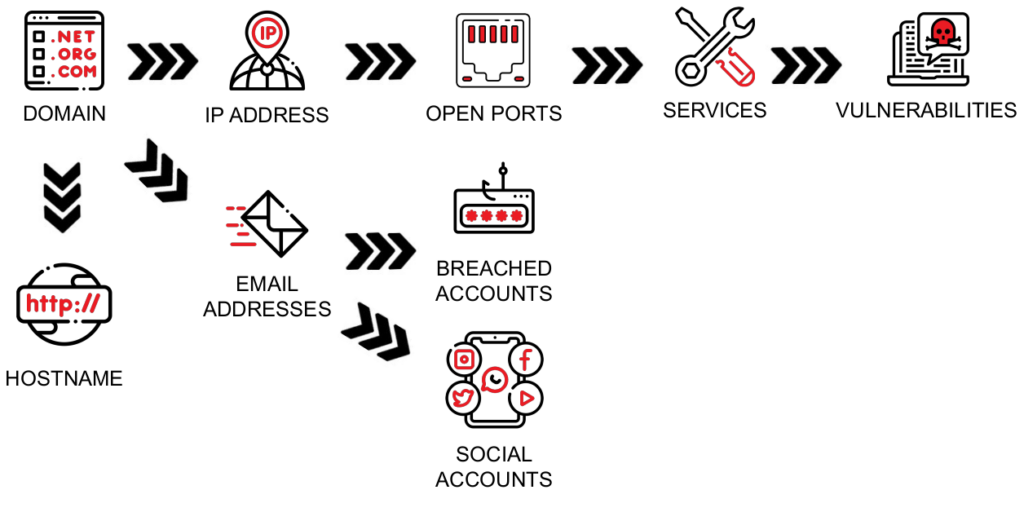
In this article, our primary focus is on infrastructure knowledge, specifically IP addresses and host names. These two elements are closely related, as each can be used to discover the other. By resolving known host names we can obtain the corresponding IP addresses and vice versa, and we can identify all the services hosted on a particular IP address.
To collect this information, we can adopt various techniques:
- DNS brute force query
- Search engine interrogation
- Archived data extraction
- IP address resolution
DNS Brute Force
Among these techniques, the most commonly used one involves taking the domain of the target and generating numerous potential subdomains by combining it with a list of words. These newly generated subdomains are then submitted to a DNS server for resolution. If DNS returns the IP address of the queried hostname, it confirms its validity.
The key advantage of this technique is its ability to uncover even the most recent subdomains. However, it does have one limitation: its effectiveness relies heavily on the comprehensiveness of the adopted list. To overcome this limitation and achieve better results, it’s recommended to utilize various tools that employ their own lists.
Search Engines and Data Archives
Another approach involves discovering valid subdomains indexed by search engines or data archives.
Interrogating a search engine is a simple and common practice that people engage in daily when they turn to Google to find information. However, there is a more advanced method for conducting research known as “Google Dorks,” which allows for targeted queries to obtain precise results. It’s important to note that Google is not the sole search engine available; alternatives such as Bing, Yandex and Baidu exist. Additionally, there are specialized search engines like Shodan, ZoomEye and Censys that cater to internet services and devices.
Data archives, in contrast, cater to a more specialized audience compared to search engines and often require a subscription to access their data. An example of such an archive is VirusTotal. While its primary objective is to inform users about the maliciousness of specific files, premium users also have the opportunity to explore the entire collection of documents uploaded to the platform. Regardless, VirusTotal extracts valuable information from the uploaded content, enabling users to search for contextual data related to IP addresses or domains, including host names.
This approach also allows you to find subdomains that are no longer active or that are offline while you are performing the research.
IP Address Resolution
The last technique outlined in this article involves resolving IP addresses into their corresponding host names. The IP addresses to be used are those belonging to the subnetworks directly managed by the target organization. These subnets can be identified by resolving the target’s domain or the subdomains already collected into their respective IP addresses. However, it’s important to note that the target may not necessarily own all the networks discovered during this process. In fact, many companies often choose to rely on cloud and hosting solutions instead.
By examining the information contained in the records managed by the appropriate Regional Internet Registry, it’s possible to identify the suitable networks for executing the reverse process. The subnet name, remarks, and registrant fields are typically the most significant indicators. If the network name includes the target name, it becomes feasible to search for other networks that share the same name.
Conclusion
Once the initial phase is complete, we will have gained a high-level understanding of the target’s perimeter. Now it’s time to delve deeper and determine which machines can be exploited. This can be achieved by identifying the open ports on the hosts, determining the version of the exposed services, and checking for any vulnerabilities they may have. For more detailed information, get ready to dive into our upcoming article. Don’t miss out – it will be worth the wait!
These Solutions are Engineered by Humans
Did you learn from this article? Perhaps you’re already familiar with some of the techniques above? If you find security issues interesting, maybe you could start in a cybersecurity or similar position here at Würth Phoenix.

Francesco Pavanello
Hi, I'm Francesco, and I'm currently working as a Cyber Threat Intelligence Engineer at Würth IT Italy.
Author
Latest posts by Francesco Pavanello
03. 07. 2026
AI, SEC4U, Threat Intelligence
The AI Cyber Attacks Explosion in 2026: Emerging Threats
26. 09. 2023
Exposure Assessment, SATAYO, SEC4U, Threat Intelligence
Exposure Assessment: How to Identify Infrastructure Vulnerabilities