
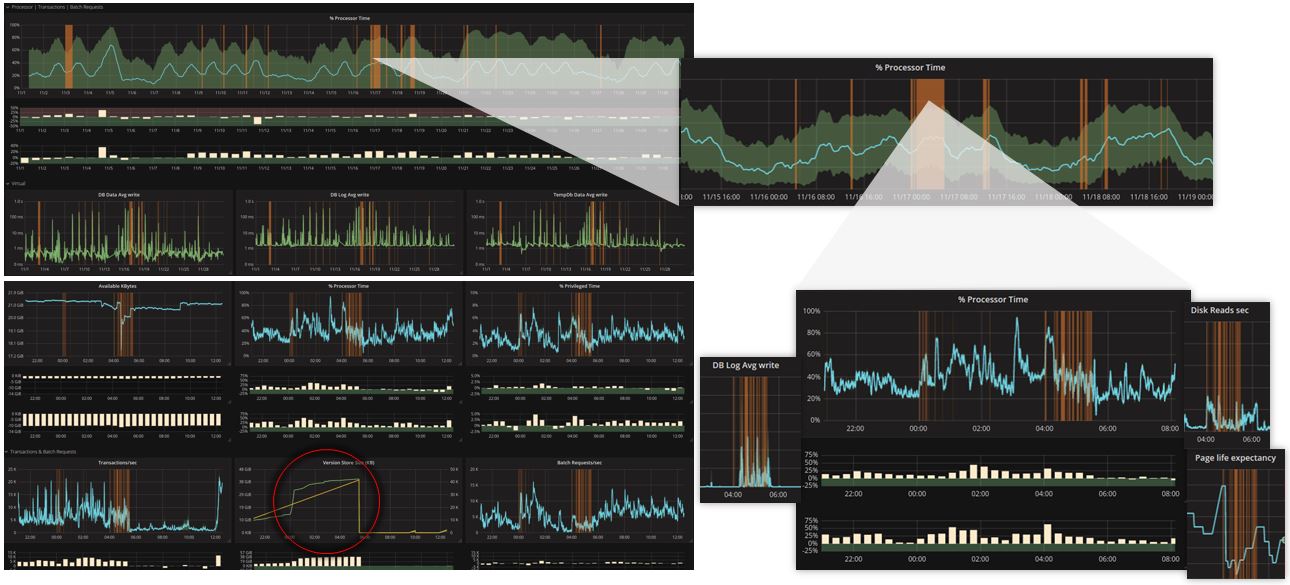
Recentemente Grafana e InfluxDB sono stati integrati nella nostra soluzione di IT System Management NetEye. Questa decisione è motivata dai elevati livelli di flessibilità e varietà offerte dalla combinazione di questi due strumenti open source. Oltre a Log Management, Inventory & Asset Management, Business Service Management e altri, ora NetEye offre anche un modulo IT Operations Analytics. In questo articolo vorremmo condividere con voi alcuni trucchi con cui diventa ancora più facile percepire la vera potenza di Grafana quando si sperimenta con le nuove dashboard in NetEye.
Grafana è il punto di riferimento del futuro quando si tratta di visualizzare serie temporali o metriche. Paragonate ad analisi offline, le dashboard di Grafana sono molto versatili e permettono trasformare immense mole di dati in modo che diventino facili da interpretare.
Quando si cerca di creare una dashboard Grafana ci sono alcuni punti da rispettare per ottenere un risultato davvero soddisfacente e una user experience altamente positiva.
Vanno evitate dashboard molto complesse, che possono risultare troppo lente e di difficile interpretazione. È preferibile avere più dashboard legate tra loro che permettano di partire da una visione generale e poi poter entrare più in dettaglio in fase di analisi.
UTILIZZARE GROUP BY
Grafana è intrinsecamente ottimizzato in un modo che non vengono mai caricati più dati del necessario. Questo significa che finché il grouping automatico (GROUP BY time($interval)) è attivato, il sistema tenta sempre di derivare la quantità di dati necessari per una visualizzazione ottimale considerando la risoluzione dello schermo, le dimensioni del panello e la finestra di tempo. Se si necessita di una densità maggiore dei data point si può’ scegliere un valore diverso per il grouping. Va tenuto in considerazione che ogni data point in più’ che viene caricato è un data point che fa durare in più’ il caricamento dei dati. L’occhio umano dopo una certa densità di data point non è più’ in grado di distinguerli.
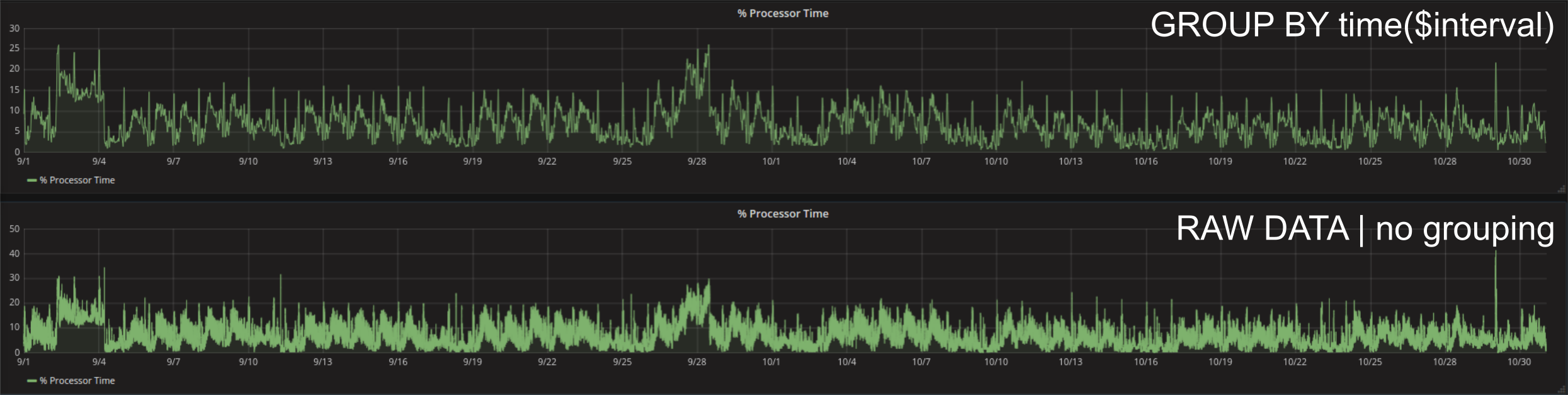
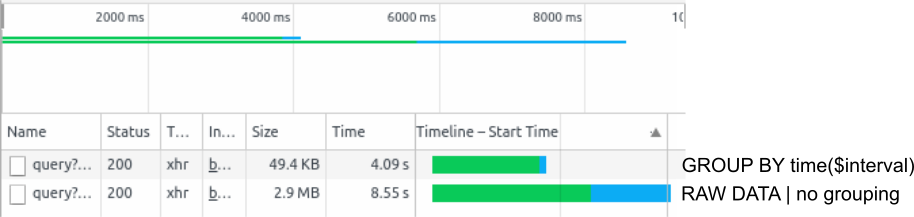
Il modo più semplice per osservare il caricamento di una dashboard Grafana è utilizzare i Chrome DevTools. Per aprirli basta schiacciare F12 mentre si naviga con il browser Chrome. Un aggiornamento del dashboard attuale (F5) mostra esattamente in che ordine e con che tempistiche le richieste vengono inviate al database e quanto durano le rispettive risposte. Per esempio: 2 mesi della metrica % Processor Time con il grouping automatico vengono caricati con una frequenza di un punto ogni 30 minuti. In questo caso i data point da trasferire sono ca. 49,4 KB. Le stessa richiesta senza grouping risulta nel caricamento di tutti data point disponibili nell’intervallo. Per esempio se sono stati registrati con una frequenza di 2s risultano 30 x 60 x 24 x 61 = 2635200 data point: 2.9 MB. Per questo motivo la seconda richiesta dura di più’.
 UTILIZZARE TRASFORMAZIONI E UNITA’
UTILIZZARE TRASFORMAZIONI E UNITA’
Per rendere più facile l’interpretazione delle curve mostrate è possibile aggiungere un’unità di misura a ogni asse y. Ogni grafico ha fino a 2 assi y e le loro unita possono essere scelte in maniera indipendente.
In più’ Grafana offre delle trasformazioni come per esempio la moving average. Questa per esempio può essere usata per uno smoothing della curva che rende più’ visibile i trend dei dati. Moving average non è altro che una finestra di una lunghezza specificata che poi viene spostata lungo la serie temporale. Con ogni spostamento viene calcolata la media di tutti i punti all’interno della finestra. Singoli punti molto estremi in questo modo diventano meno visibili e la dinamica della curva più’ chiara.
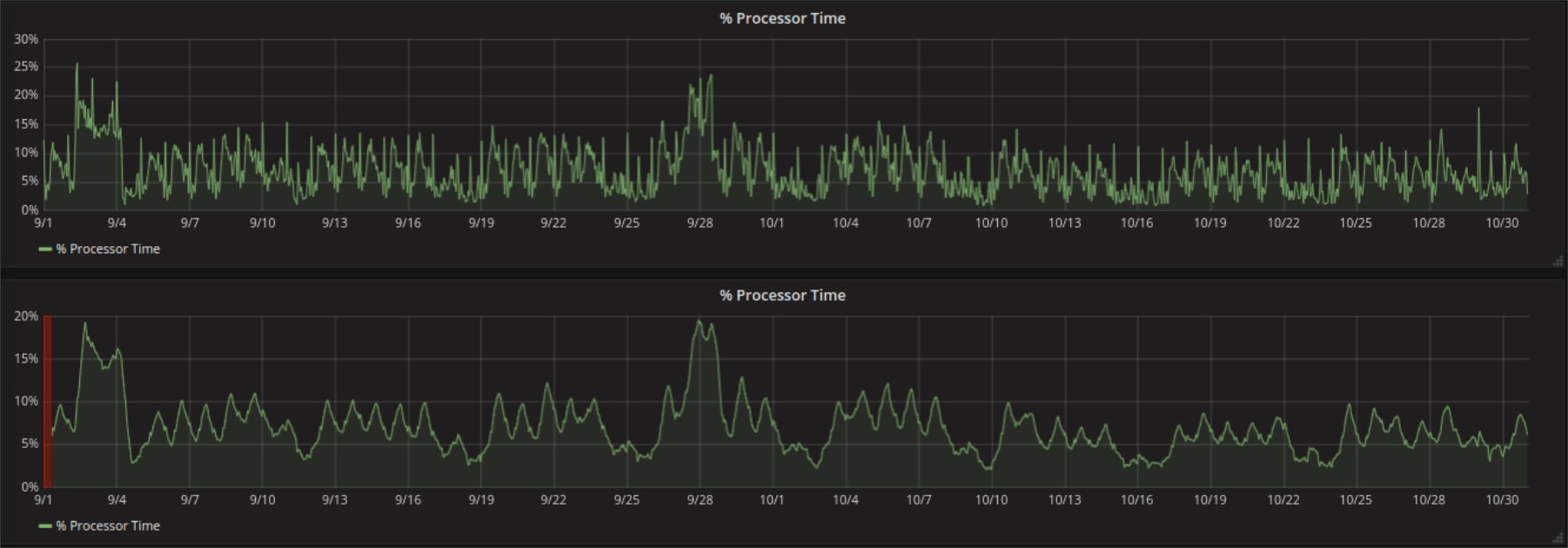
Un punto da rispettare è che con l’applicazione della finestra viene introdotta una specie di shift della serie. In particolare se il valore scelto per grouping è alto e una finestra larga producono risultati matematicamente logici ma poco desiderabili. (area arancione). Perché si forma questo buco all’inizio? Grafana (per lo meno se usato assieme a InfluxDB) non permette di specificare la larghezza della finestra in secondi, ma solo il numero di punti che devono essere presi in considerazione per la media. Il primo moving average può quindi essere calcolato dopo esattamente questo numero di punti disponibili. In unità di tempo questo corrisponde alla moltiplicazione della larghezza della finestra con il valore scelto per il grouping.
Cerchiamo di illustrarlo con un’esempio:
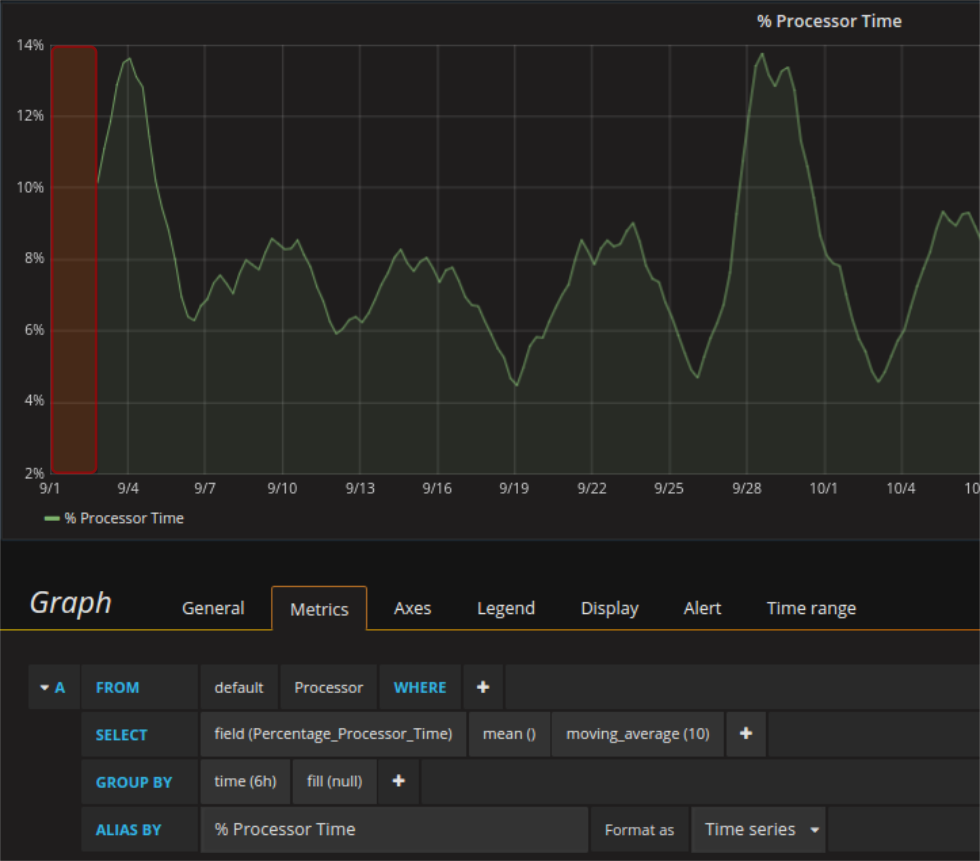
La richiesta che produce i dati per il grafico ha un valore di 6h per il grouping (perciò senza moving average InfluxDB manderebbe un valore medio dei dati per ogni 6h di dati registrati). Se invece si vuole usare anche una moving average con larghezza 10 della finestra, InfluxDB applica un’ulteriore media sempre a 10 di questi punti che avrebbe mandato in precedenza). Per la prima volta questo è possibile dopo 10 valori dal database sono disponibili (quindi dopo 6h x 10 = 6- h = 2.5d di registrazione). Grafana mostra il valore ottenuto non al centro della finestra ma alla sua fine. Quindi il primo valore ottenuto è spostato di mezza finestra (2.5d / 2 = 30h) e all’inizio della serie temporale si forma un buco largo quanto la finestra. Applicando uno zoom la larghezza della finestra (in termini di tempo, non di punti) può’ cambiare se si usa il grouping automatico. Questo può rendere un pò perplessi quando visto per la prima volta.
CONSIDERARE CHE INFORMAZIONE SI VUOLE EFFETTIVAMENTE FAR VEDERE
La media (come la moving average) è uno dei tanti modi per visualizzare che cosa sta(va) succedendo in un determinato intervallo di tempo. Per alcune metriche può essere interessante non solo che cosa è successo in media, ma in che range i valori si sono mossi.
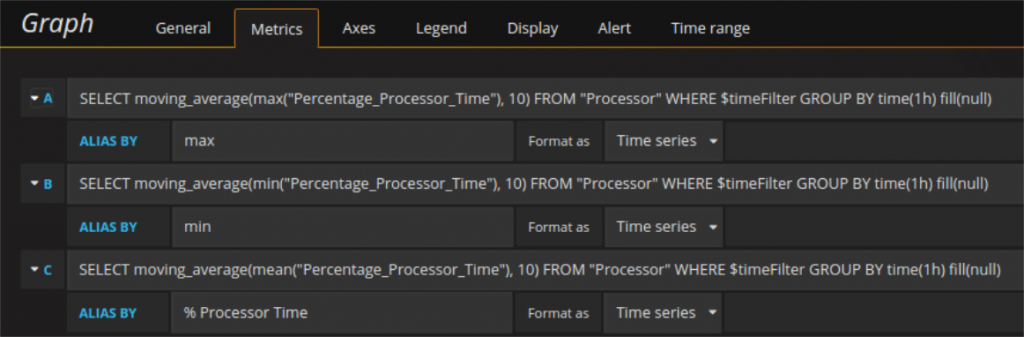
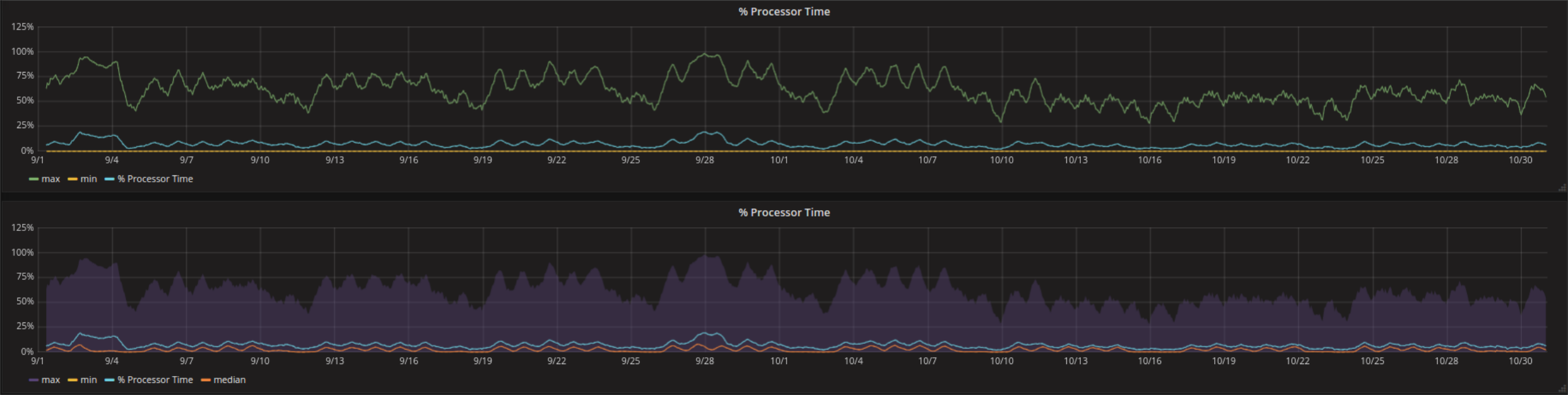
Tutto quello che vale per la media, si può’ applicare anche al massimo e/o minimo della serie temporale:
Troppe curve simili nello stesso grafico aumentano la confusione. Si può pensare all’introduzione di trasparenza parziale di quelle meno importanti. In caso di un range anche l’area fra due curve (nel esempio fra massimo e minimo) può essere molto informativo e più’ facile da interpretare.
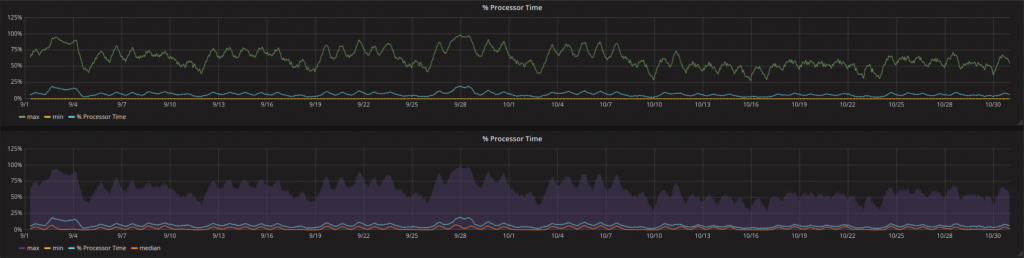
Una visualizzazione di questo tipo può essere configurata nelle Series Overrides. Tutto l’occorrente viene fatto dalla opzione fill_below_to. La curva in basso può essere nascosta mettendo Lines su false.
Non bisognerebbe esagerare con aree di questo tipo in particolare se si usano funzioni come percentile invece di max e min, perché si notano molto nel tempo che la dashboard ci si mette per caricare.



OTTIMIZZAZIONE DEL CONTATTO CON IL DATABASE
Le stesse curve (o meglio i loro valori) possono essere richiesti in più modi al data base. Per esempio la media, il massimo e il minimo possono essere recuperati con tre singole richieste e ognuna di esse ritorna i timestamp con i rispettivi valori. In alternativa tutti e tre possono essere recuperati con una singola richiesta che ritorna i timestamps e tre colonne di valori: una per media, max e min rispettivamente. Anche in questo secondo caso è possibile usare l’aliasing. Basta importare un alias per ogni campo (con AS) e importare il campo comune del alias per la richiesta con $col. In questo modo i series overrides funzionano nella stessa maniera per entrambi i tipi di richiesta descritte sopra. Per richieste che hanno pochi data point come ritorno non farà’ tanta differenza, ma l’utilizzo mirato di uno o l’altro metodo può’ cambiare molto la performance di dashboard più complesse.
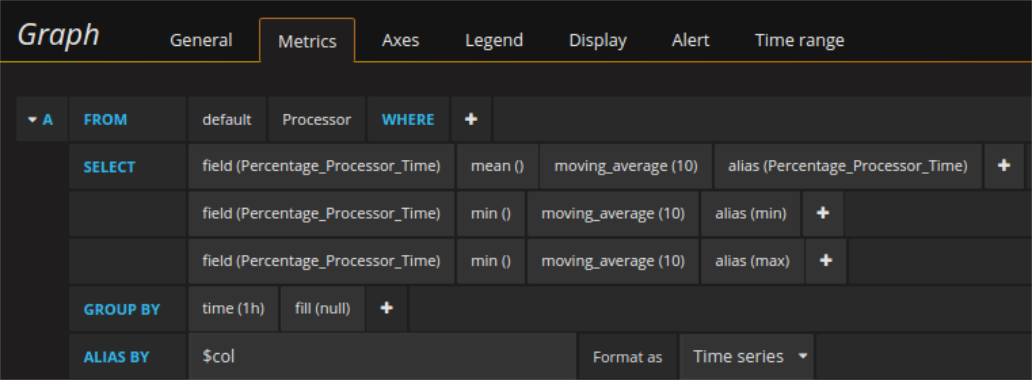
Per esempio quando si fanno le stesse richieste più’ volte, la differenza descritta sopra è molto importante. Richieste identiche per esempio potrebbero essere necessarie, perché si vuole scalare due grafici nella stessa maniera e non si possono (ancora) usare variabili per i limiti dell’asse y. Così, caricando due curve ogni volta e nascondendo la rispettiva altra sforza lo scaling uguale come in questo esempio:
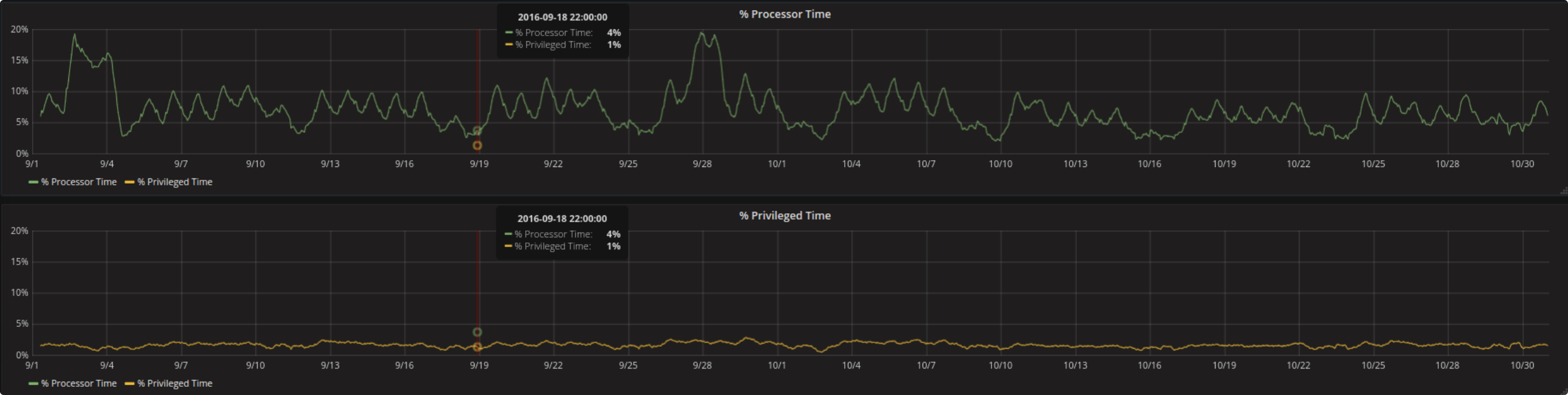
La % processor time e la % privileged time sono entrambe metriche della stessa componente (processor). Per mostrarli contemporaneamente in due grafici diversi e la stessa scala (per l’asse y) la rispettiva altra curva è sempre stata caricata assieme in maniera nascosta. Nascosto in questo contesto significa con line width messo a 0 NON lines = false altrimenti la curva sparisce e non viene considerata per lo scaling.
In un tale setting (dipende anche dalla quantità di dati) è possibile che il primo grafico (mentre sta caricando il risultato della richiesta) blocca il caricamento dei dati del secondo. Per poter evitare problemi di questo tipo conviene di nuovo utilizzare i DevTools.
CARICAMENTO PARZIALE DELLA DASHBOARD
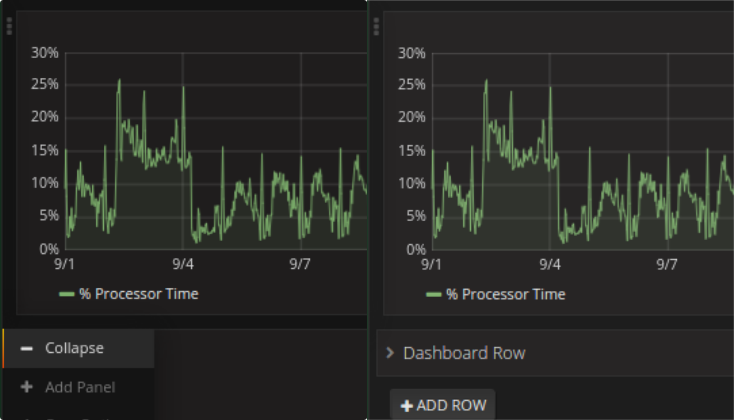
Quando una dashboard contiene molti panelli conviene raggrupparli in row. Se il contenuto di alcuni panelli è più importante di altri conviene posizionare in alto queste poche importanti e fare un collapse delle row più basse in maniera che quelle vengono solo caricate quando aperte per la prima volta.
CONCLUSIONI
Durante la creazione di una dashboard è essenziale considerare l’utente, per decidere parametri come la risoluzione necessaria e simili. Se non è possibile lasciare il grouping su auto. Un’alternativa può essere una variabile (in Grafana chiamata template) per quel valore che è impostato su un valore che permette un caricamento veloce all’inizio. Se poi l’utente ha cmq bisogno di più dettagli può sempre cambiare il valore in futuro (quando tempo lunghi non sono più cosi gravi, perché per lo meno si sa già che si sta indagando il periodo d’interesse).
Trasformazioni e maths sono utili per rendere le curve interpretabili al volo.
I Chrome Dev Tools sono lo strumento più importante per il debugging di una dashboard Grafana.







Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential