
Artificial Intelligence (AI) refers to hardware or software that exhibits behavior which appears intelligent. Machine Learning is a field of computer science that gives computers the ability to learn without being explicitly programmed. Deep Learning is part of a broader family of machine learning methods based on learning data representations, as opposed to task-specific algorithms.
Gartner acknowledges Deep Learning to have delivered technology breakthroughs recently and they regard it as the major driver toward artificial intelligence.
One can expect a significant impact on most industries over the next three to five years. It’s just one more reason to act now and understand its real potential. Below I will answer the three questions I have been asked most often about deep learning over the last few months.

Susanne Greiner, Wuerth Phoenix @ Deep Learning BootCamp with experts from Google, Nvidia & Zalando Research, Dresden 2017
What is Deep Learning?
All Machine Learning algorithms learn through training. Usually examples with known outputs (labels) are used to train the algorithm, which is then used to predict the labels of new examples. The quality of the prediction therefore improves with more data (experience). Traditional ML methods are often limited by the fact that we are unable to specify the features well enough. What does that mean? Think about a person who has never seen a dog before. You might explain what a dog should look like, how it ought to behave, and so on. There might be important features like barking, a tail, fur, and then other less important ones. The human brain can learn the concept dog through training and now – thanks to modern GPUs and artificial neural networks – computers can, too.
A standard ML algorithm receives labeled examples as inputs, compares its predictions to new, correct outputs, and tunes the weightings of the inputs to improve the accuracy of its predictions until they are optimized. Thus the quality of the predictions improves with experience. The more data we provide (at least, up to a point), the better the prediction engines that we can create. If we write a computer program that identifies images of dogs, we cannot specify the features of a dog for an algorithm to process that will enable correct identification in ALL circumstances. With deep learning, the data optimization and feature specification is shifted from the programmer to the program. It’s a key concept of the success of these methods.
How does deep learning work?
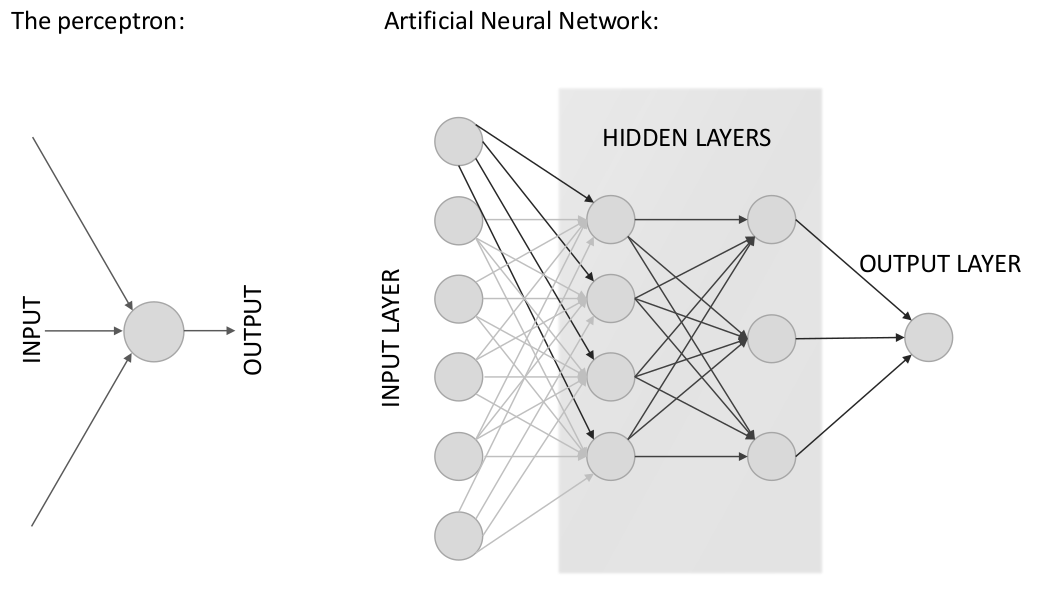
The human brain is made up of neurons, while an artificial neural network is made of perceptrons. Each perceptron has a set of inputs, each of which is given a specific weight. The perceptron computes some function over these weighted inputs. A neural network is created when we start hooking up perceptrons to one another, to the input data, and to the output which corresponds to the network’s answer to the learning problem. The layers that are neither input nor output are called hidden layers.
Each hidden unit can affect the final output. We don’t know what the hidden units ought to be doing, but what we can do is compute how fast the error changes when we change something in the hidden layer. This is where backpropagation comes into play.
How can deep learning be used?
We are currently applying state-of-the-art ML methods to performance monitoring data. Our particular interest lies in the combination of performance metrics and user experience. In short, active real user experience gained by our Alyvix solution (www.alyvix.com) can be used to improve ML algorithms that analyze the performance metrics of several servers because it marks critical time ranges as such even if no user is currently complaining.
For example, the test below checks every few minutes whether several important steps of a business-critical application are performing properly. The performance of each step is written into InfluxDB and can be easily used together with performance metrics from the same system to detect why the system was slow during some time periods.

To learn from problems we know about and problems that have yet to occur is very challenging and interesting, and it is here that deep learning methods are at their most promising.
In case you are interested in finding out more about deep learning, feel free to attend (or watch) my presentation at SFScon 2017 on Friday, the 10th of November (https://www.sfscon.it/).







Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential