10. 07. 2026
APM, Log Management, Log-SIEM

09. 10. 2023
Davide Sbetti
Log-SIEM, Machine Learning, NetEye
Semantic Search in Elasticsearch – Testing Our NetEye Guide: Can We Improve the Search Experience? (Part 2)
In my previous blog post, we saw how it’s possible to index some documents that we created by crawling our NetEye User Guide, then applying the ELSER model in Elasticsearch to create a bag of words for searching that takes into account the context of the various documents.
Moreover, we also performed a simple query to ensure we’re actually able to search our documents, applying the same model to the query as well. But since our goal is to integrate all this in order to search our User Guide, our work is still not done! In this POC, let’s try to modify Sphinx’s default search to use Elasticsearch.
Sphinx Search
Let’s start by noting how our User Guide is built around Sphinx, a documentation generator built in Python. By looking at the source code of our User Guide, and obviously at the documentation itself, we can see how the logic of the search is included in the search.html file. Here the default Sphinx approach is applied that returns, for the query passed as URL parameter, the documents matching the query, based on an index built when Sphinx generates the HTML files.
Okay, so at this point we can simply replace the code in the file search.html to call a custom endpoint which we will create to handle the queries and results from Elasticsearch. Why an endpoint? Because for security reasons, it would be better to avoid any direct contact between the search page and the Elasticsearch instance managing our documents.
We can thus replace the code creating the search results using Sphinx default’s approach, with something like this:
const query = getUrlVars()["q"];
const url= 'http://localhost:8888/query?q=' +
encodeURIComponent(query);
$.ajax({url: url, success: function(result){
if (result.length) {
result.forEach((result) => {
let result_item = $("<li />");
const result_link = $("<a />",
{href: result.href}).text(result.caption);
const result_context = $("<div />",
{"class": "context"}).text(result.context);
result_item.append(result_link);
result_item.append(result_context);
$("#search-results").append(result_item);
});
}
}});
In the code above we are just sending the query string to a custom endpoint, which for this test was running on my local machine, and then displaying the results, which are composed of the following attributes:
- Direct URL to the section
- Title of the section
- Context of the result
And yes, for this POC this is enough to show the results on Sphinx, as we will see shortly.
A Custom Endpoint to Expose the Results
As mentioned above, a custom endpoint is also useful from a security perspective, since it allows us to control the queries that are made to our Elasticsearch instance.
Also in this case, we’ll use Python and a library, flask, to expose the endpoint that we will use in our tests.
Let’s start by importing the necessary libraries and setting some variables (we’ll see then why we need them, I promise). And yes, for this POC we’ll hard code the version of the User Guide that we’ll query since we only crawled one!
from flask import Flask, request, jsonify
import json
from elasticsearch import Elasticsearch
import sys
CONTEXT_SENTENCE_LENGTH = 30
CONTEXT_SENTENCE_JUMP = int(CONTEXT_SENTENCE_LENGTH / 2)
es_client = Elasticsearch('https://localhost:9200')
app = Flask("Local UG Search Server")
neteye_version_to_query="4.32"
userguide_base_url =
f"https://neteye.guide/{neteye_version_to_query}"
After that, we can add a query endpoint that will handle the incoming queries. It will first of all run the query and then parse the received results, extracting the context sentence that we would like to display, since Elasticsearch’s text expansion does not return us a “summary” or “matching sentence” for the results. After that, we can just return our results as a JSON response.
@app.route("/query")
def query():
query_string = request.args.get('q')
hits = run_query(query_string)
search_results = [
extract_search_result_with_summary(
hit,
query_string
) for hit in hits
]
response = jsonify(search_results)
response.headers.add('Access-Control-Allow-Origin', '*')
return response
Okay, so now it’s time to run the query the user performed through the search bar. We can just prepare it as a JSON request containing the model that we would like to apply and the query string, sending it to our Elasticsearch instance using the official Elasticsearch Python client that we already used during the crawling phase. After that, we can return the hits that our query returned.
def run_query(query_string):
es_query = {
"text_expansion":{
"ml.tokens":{
"model_id":".elser_model_1",
"model_text": json.dumps(query_string)
}
}
}
es_query_fields = ["page", "text", "ml.tokens", "title"]
es_query_fields_collapse = {"field": "page" }
response = es_client.search(
index=f"neteye-guide-{neteye_version_to_query}",
query=es_query,
size=10,
sort="_score:desc",
fields=es_query_fields,
source=None,
collapse=es_query_fields_collapse,
source_excludes="*"
)
# map responses
if not "hits" in response or not "hits" in response["hits"]:
return []
return response["hits"]["hits"]
Okay okay, so we’ve got the hits/results of our query. This means we can now map each result to… a title and a context sentence! As you’ll remember, we already embedded in the documents the title or caption of the sections we crawled, so the title is the easy part!
def extract_search_result_with_summary(
search_result,
query_string
):
summary = extract_summary_from_search_result(
search_result['fields']['text'][0],
search_result['fields']['ml.tokens'][0],
query_string
)
link = search_result['fields']['page'][0]
title = search_result["fields"]["title"][0]
return {
"href": f"{userguide_base_url}/{link}",
"caption": title,
"context": summary
}
And so yes, as you will have discovered most of the logic is in the function extract_summary_from_search_result. So, how can we extract the context sentence from the 256 raw words that we received?
Hmmm, honestly, I thought a bit about this when developing the POC, and the first thing that we could try, being lazy just this once, is to re-use the scores that ELSER assigned to the words in its dictionary! Because as you remember, for each search result ELSER returns not just the result text but also the scores of the various words in its dictionary for that specific result, as we can see also from the image below:
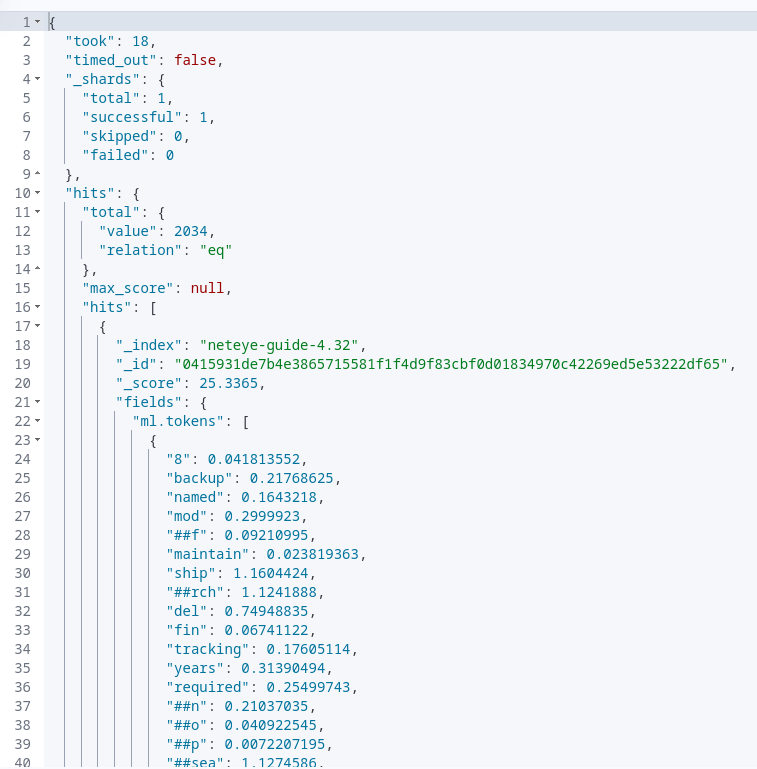
So, how can we use the scores?
Well, we can create some sentences, or better parts of sentences (that from now on we will call excerpts), from the 256 words that we received from the search result and give weight to the excerpts, by summing up the weights of their single words according to the scores given by ELSER for the result!
Yes, I know, this is leaving out the context part, since some of the words with a large score might not also be part of the text. But they might rather be context words….. but since we cannot incorporate them into a text in which they were not present, we can live with this, for now.
The last question that we need to ask ourselves is: How can we create the candidate excerpts to find our ideal context for the result?
Well, in a quite lazy and simple way, we could re-use the same approach that we used when crawling. So sliding through the text and creating excerpts of a fixed length (in our case 30 words), moving every time ahead by say, 15 words.
I know I know, you may wonder how I chose those numbers, right? Well, maybe they won’t be ideal and work in all cases, but the idea behind them is that 15 words is the recommended sentence length, according to some established research. So, with the criteria mentioned above, the context of each result will be around two sentences in length.
Okay, so now that we have this idea clear in our minds, we can formulate it in code:
def extract_summary_from_search_result(
text,
tokens,
query_string
):
# Naive extraction from tokens,
# we build sentences of 30 words and we take the one with
# the largest weight
context_sentence = None
current_sentence_start = 0
context_sentence_weight = -sys.maxsize
# transform text to array of words
words = text.split()
while current_sentence_start < len(words):
# compute current sentence
current_sentence = words[
current_sentence_start:
current_sentence_start + CONTEXT_SENTENCE_LENGTH
]
# compute current sentence weights
weights = [
tokens.get(word.lower(), 0)
for word in current_sentence
]
current_weight = sum(weights)
if current_weight > context_sentence_weight:
context_sentence = current_sentence
context_sentence_weight = current_weight
# check start of sentence
if current_sentence_start != 0
and words[current_sentence_start - 1][-1] != ".":
context_sentence = ["..."] + context_sentence
if context_sentence[-1][-1] != ".":
context_sentence = context_sentence + ["..."]
current_sentence_start =
current_sentence_start + CONTEXT_SENTENCE_JUMP
return context_sentence
And now… YES! We are ready to test our POC and try to perform the same search that we did at the end of the previous blog post, just from the UI this time!
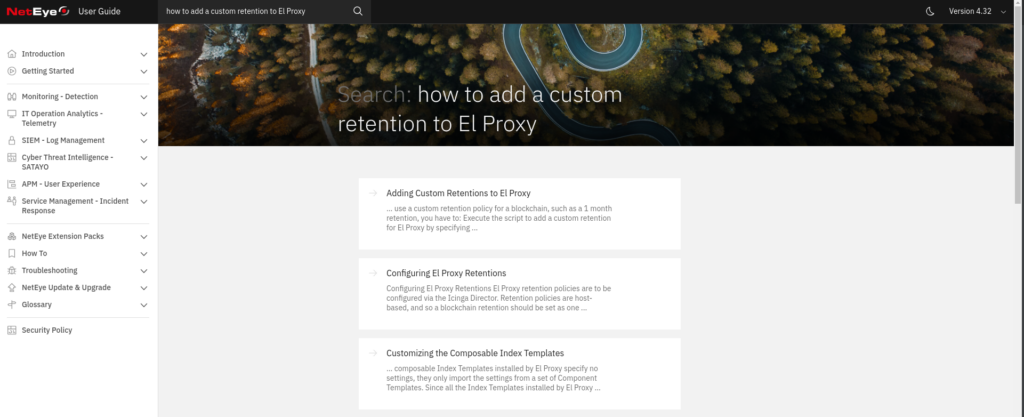
Conclusions
In these two blog posts, we saw how it’s possible to index documents in Elasticsearch while also applying the ELSER model through an ingest pipeline to obtain bags of words that can then be used to apply a semantic search approach, and also taking into consideration the context of the queries we are evaluating.
Moreover, we saw how to apply it to our User Guide, creating a simple POC to show a potential integration with our search procedure.
If you read up until this point, I’d like to thank you for going on this little adventure with me. See you soon!
These Solutions are Engineered by Humans
Did you find this article interesting? Does it match your skill set? Programming is at the heart of how we develop customized solutions. In fact, we’re currently hiring for roles just like this and others here at Würth Phoenix.
Davide Sbetti
Hi! I'm Davide and I'm a Software Developer with the R&D Team in the "IT System & Service Management Solutions" group here at Würth IT Italy. IT has been a passion for me ever since I was a child, and so the direction of my studies was...never in any doubt! Lately, my interests have focused in particular on data science techniques and the training of machine learning models.
Author
Latest posts by Davide Sbetti
30. 06. 2026
AI, Kubernetes
Load-balancing Requests to LLMs in Kubernetes: A KV-cache Approach with llm-d!
30. 03. 2026
APM, Log Management, Log-SIEM, NetEye
Sending OTel Data to Elasticsearch: Tenant Segregation through OAuth