





31. 03. 2026
Log-SIEM, NetEye, Unified Monitoring

17. 02. 2017
Susanne Greiner
NetEye
Grafana Dashboard Tuning: aussagekräftige Informationen statt einem Haufen Daten
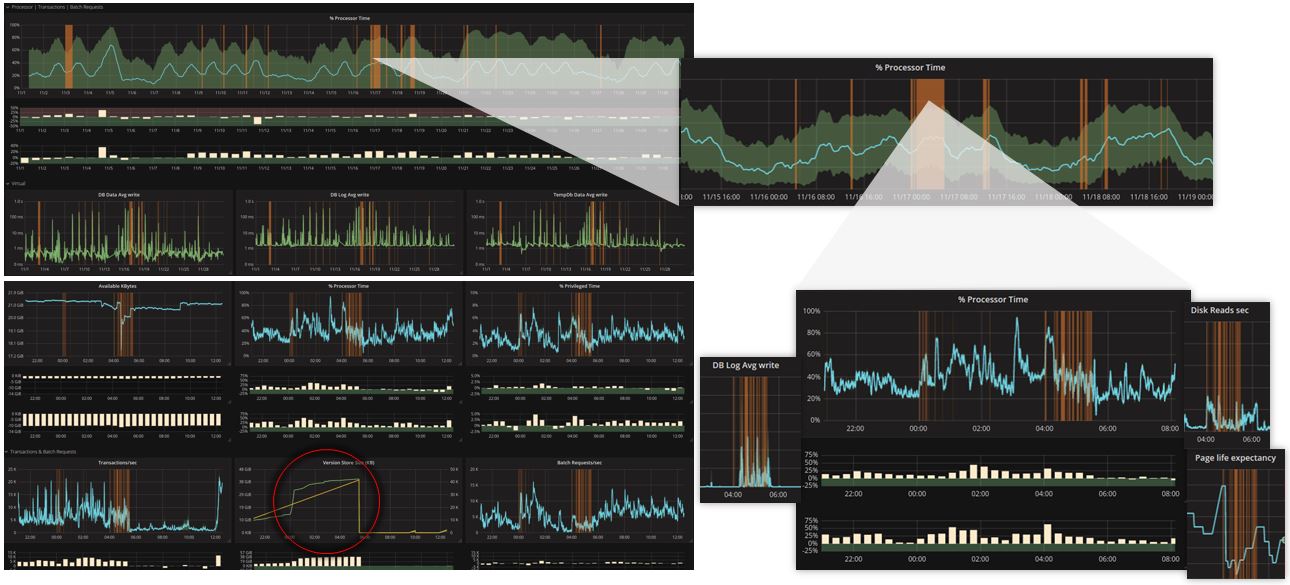
Grafana und InfluxDB sind jetzt in unsere IT System Management Lösung NetEye integriert. Diese Entscheidung wurde hauptsächlich getroffen, weil Grafana & InfluxDB in Kombination einen sehr hohen Grad an Flexibilität und Anpassung bieten. Neben dem Log Management, Inventory & Asset Management, Business Service Management und weiteren, bietet NetEye nun auch ein IT Operations Analytics Modul. In diesem Artikel wollen wir ein paar Tricks weiter geben, mit denen sich die Möglichkeiten von Grafana noch besser ausreizen lassen, wenn man mit dem neuen Grafana Dashboards in NetEye etwas experimentieren will.
Grafana steht für den neuesten Stand der Technik wenn es um die Visualisierung von Zeitreihen und Metriken via Requests an eine unterliegende Datenbank, wie z.B. InfluxDB, geht. Im Vergleich zu Offline Analysen sind Grafana Dashboards sehr vielseitig und es wird möglich extrem große Datenmengen auf eine Art und Weise anzuzeigen, die die Interpretation für den Zuständigen sehr einfach macht.
Beim Dashboard-Erstellen gibt es ein paar Punkte, die beachtet werden sollten, damit eine mehr als zufriedenstellende User Experience garantiert ist und nicht einfach eine sehr große Zahl komplizierter Dashboards mit tausenden von Metriken und viel zu hoher Genauigkeit entstehen, nur weil das mit Grafana als Tool nun möglich ist. Dashboards, die zu lange laden, werden nie viel Beachtung finden, auch wenn sie Einiges an relevanten Informationen beinhalten.
VERWENDUNG VON GROUP BY
Grafana ist von Haus aus so optimiert, dass nie mehr Daten geladen werden, als tatsächlich benötigt werden. Das heißt, so lange das automatische Grouping (GROUP BY time($interval)) verwendet wird, wird immer versucht, basierend auf der Bildschirmauflösung und der Größe des Panels exakt die Anzahl an Datenpunkten aus der Datenbank zu laden, die für eine hochqualitative Darstellung der Kurve im gewählten Zeitintervall notwendig sind. Sollte eine höhere Datendichte erforderlich sein, kann ein passender Group By Wert von Hand gewählt werden, aber man sollte bedenken, dass jeder Punkt, der mehr geladen werden muss (z.B. maximale Genauigkeit und kein Grouping) den Ladeprozess negativ beeinflusst und das menschliche Auge ab einer gewissen Genauigkeit gar nicht mehr in der Lage ist noch mehr Datenpunkte aufzulösen.
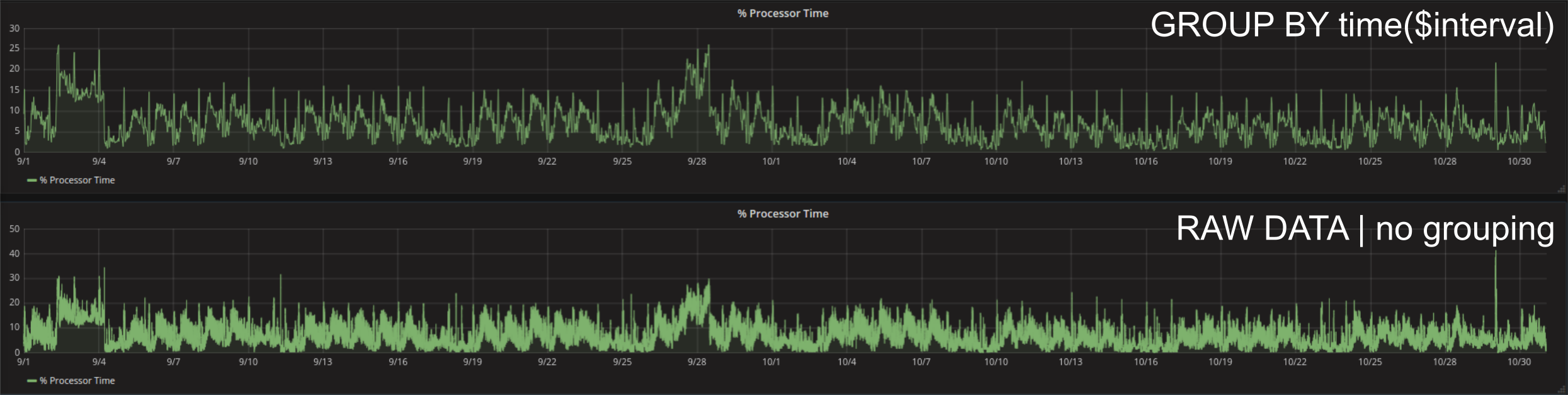
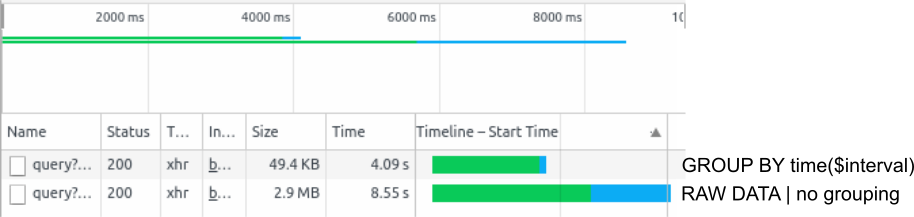
Die einfachste Art den Ladevorgang eines Grafana Dashboards zu beobachten sind die Chrome DevTools. Diese können im Chrome Browser einfach geöffnet werden, indem man F12 drückt. Ein erneutes Laden (F5) des Dashboards zeigt genau in welcher Reihenfolge die Requests zur Datenbank geschickt werden und wie lange die jeweiligen Antworten brauchen. Zum Beispiel zwei Monate Prozessor Zeit mit Autogrouping läd einen Datenpukt alle 30 Minuten. Die zu transferierenden Punkte sind in diesem Fall ca. 49,4 KB groß. Eine Anfrage ohne Grouping an die Datenbank führt zum Laden aller verfügbaren Datenpunkte aus dem Zeitraum und somit bei 2s Genauigkeit zu 30 x 60 x 24 x 61 = 2635200 Datenpunkten: 2.9MB. Dementsprechend braucht der Request im zweiten Fall um Einiges länger.
VERWENDUNG VON EINHEITEN UND TRANSFORMATIONEN
Um Daten noch interpretierbarer zu machen lassen sich der jeweiligen Datenkurve Einheiten hinzufügen. Jeder Graph hat bis zu 2 Y-Achsen, deren Einheiten auch unterschiedlich gewählt werden können.
Es stehen auch Transforamtionen wie zum Beispiel der Moving Average zur Verfügung. Dieser kann z.B. zum Smoothen der Zeitreihe und somit zur einfacheren Trenderkennung verwendet werden. Moving Average ist nichts anderes als ein Fenster einer bestimmten Länge, dass entlang der Zeitachse verschoben wird und ein Mittelwert aller Punkte, die in das jeweilige Fenster fallen. So werden einzelne extreme Werte geglättet und die Large Scale Dynamik der Kurve wird sichtbar.
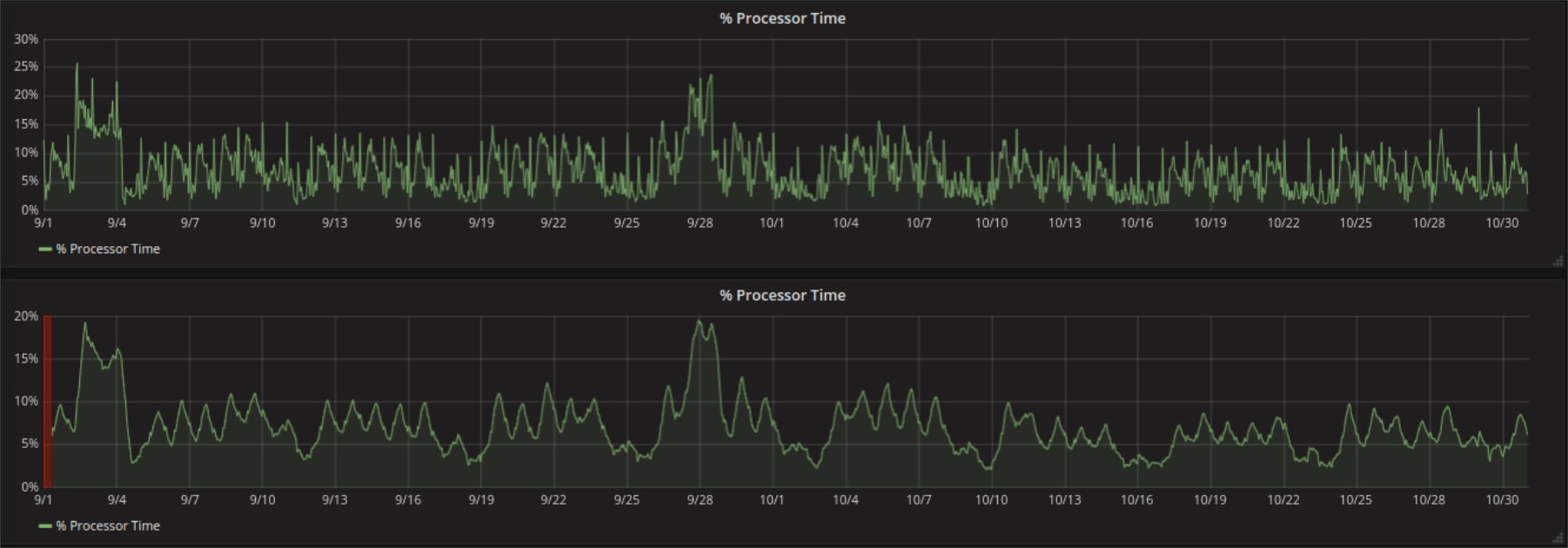
Ein Punkt, der besondere Beachtung verdient, ist, dass durch das Fenster eine Verschiebung der Datenpunkte auftritt, welche bei der Kombination eines großen Fensters mit einem hohen Group By Wert zu ungewollten Ergebnissen führen kann (orange Region). Warum ist das so? Grafana (zumindest wenn mit InfluxDB verwendet) erlaubt keine Zeitwerte für das Fenster, sondern nur einen Anzahl an Datenpunkten, die hergenommen werden soll. Der erste Moving Average kann somit nach exakt dieser Anzahl berechnet werden. In Zeiteinheiten entspricht das der Fenstergröße multipliziert mit dem Group By Wert.
Im Folgenden wird dies anhand eines Beispiels verdeutlicht:
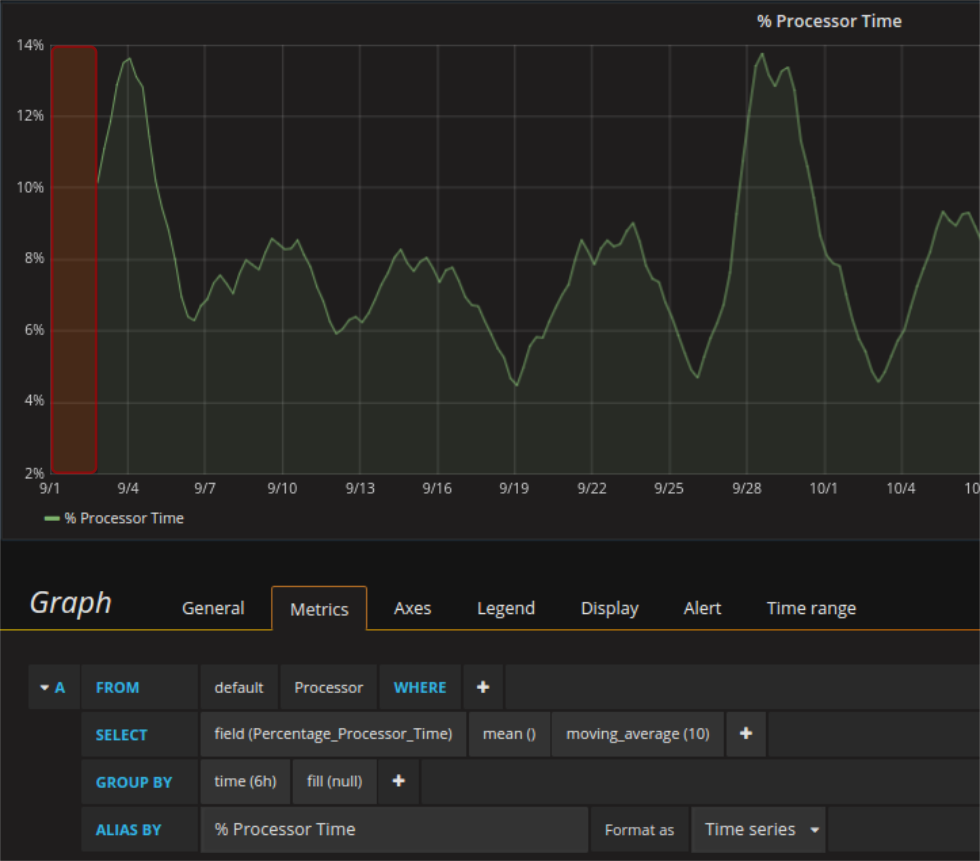
Der Request des Graphs hat einen Group By Wert von 6h (d.h. es werden jeweils für 6h Daten der Mittelwert der Daten von InfluxDB an Grafana geschickt). Wenn man einen Moving Average mit Fenstergröße 10 darauf anwendet, dann werden immer 10 aufeinander folgende Mittelwerte nochmals gemittelt. Dies ist zum ersten Mal möglich, sobald 10 Werte aus der Datenbank vorliegen (also nach 6h x 10 = 60h = 2.5d). Grafana stellt den errechneten Wert nicht in der Mitte des Fensters, sondern an dessen Ende dar. Der erste errechnete Wert ist somit um ein halbes Fenster (2.5d / 2 = 30h) nach rechts verschoben. Zoomt man hinein ändert sich (wenn auf auto) der Group By Wert und somit die Position der Werte.
WÄGE AB, WAS WIRKLICH GEZEIGT WERDEN SOLL
Der Mittelwert (oder der Moving Average) einer Kurve ist eine Möglichkeit darzustellen, was während einem bestimmten Zeitintervall stattgefunden hat. Allerdings ist für einige Arten von Zeitreihen nicht nur interessant, was im Mittel passiert, sondern auch in welchem Bereich sich die Werte bewegen. 
Was mit dem Mittelwert geht, geht ebenso mit dem Maximum oder dem Minimum:
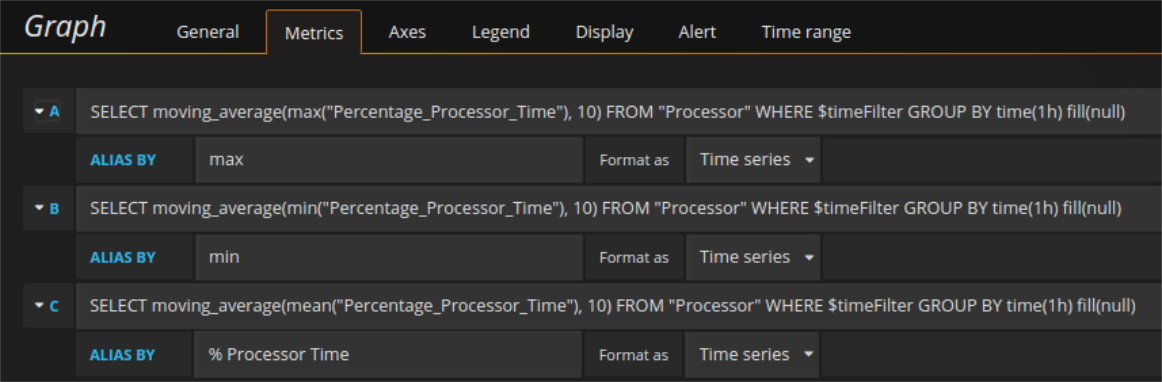
Zu viele sehr ähnlich aussehende Kurven können einen Graph leicht unübersichtlich machen. Dem kann Abhilfe geschafft werden, indem die Kurvenstruktur für die wichtigste Kurve beibehalten wird und man weniger wichtige Kurven mit Transparenz versieht oder Bereiche zwischen Kurven hervorhebt (z.B. der Bereich zwischen Maximum und Minimum als semitransparenter Bereich).
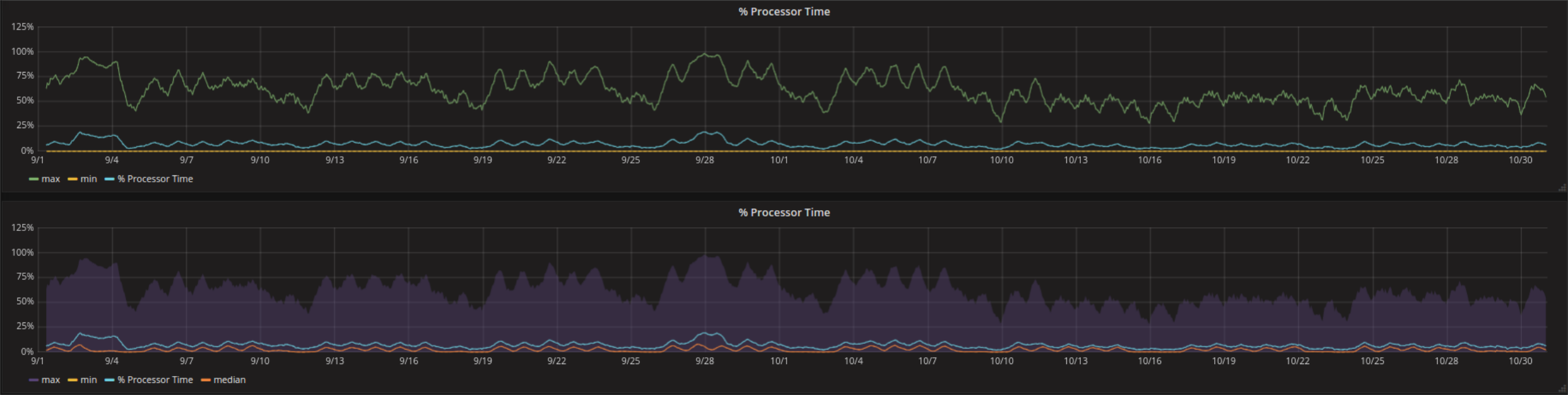
Eine Visualisierung wie diese kann in den Series Overrides konfiguriert werden. Alles was man dazu braucht ist die fill_below_to Option. Die untere Linie kann dann unsichtbar gemacht werden, indem man Lines auf false setzt.
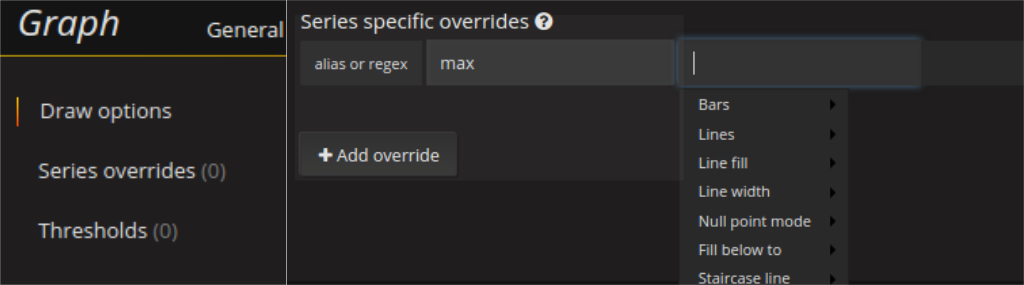
Es empfiehlt sich nicht mit solchen Bereichen zu übertreiben, weil sie sich bei den Ladezeiten sehr deutlich bemerkbar machen. Insbesondere Funktionen wie Percentile anstatt von Maximum bzw. Minimum können zu Verzögerungen führen, die sich durch nur geringe Verbesserungen der Visualisierung nicht rechtfertigen lassen.

OPTIMIERUNG DES KONTAKTS MIT DER DATENBANK
Die gleichen Kurven (bzw. deren Werte) können auf unterschiedliche Art und Weise aus der Datenbank angefordert werden. Zum Beispiel der Mittelwert, das Maximum und das Minimum können mit 3 einzelnen Requests abgefragt werden von denen jede einzelne ja die Timestamps und die jeweiligen Werte zurück bekommt. Alternativ kann die Abfrage auch als einzelner Request, der die Timestamps und drei Spalten mit je einem Wert für jede der drei zurück gibt, gemacht werden. Auch in diesem zweiten Fall ist Aliasing möglich. Es genügt für jedes Field einen Alias (AS) zu setzen und das gemeinsame Aliasfeld mit $col zu füllen. Auf diese Art und Weise funktionieren die selben Series Overrides genau wie vorher. Für Requests, die wenig Daten zurück bekommen, mag es keine große Rolle spielen, wie sie abgefragt werden, aber wenn die Datenmengen zunehmen, kann sich der gezielte Einsatz der einen oder der anderen Methode sehr deutlich bemerkbar machen.
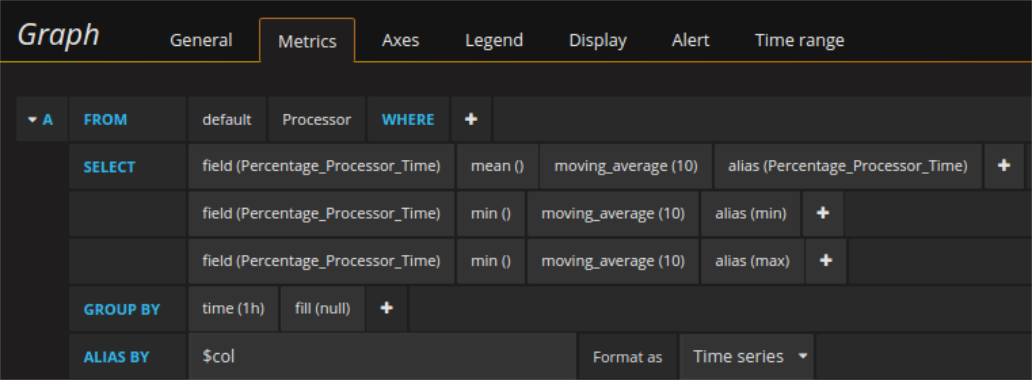
Der eben beschriebene Unterschied spielt vor allem dann eine Rolle, wenn z.B. in mehreren Graphen gleichzeitig die selbe Abfrage läuft. Ein used case ist, dass man zwei Kurven gleich skalieren will und keine festen y-Limits verwenden möchte. In diesem Fall ist (da man noch keine Variablen als Limits verwenden kann) die einzige Möglichkeit, in beiden die jeweilige andere Kurve auch abzufragen und versteckt ins Dashboard mit hinein zu laden (nur um beides Mal gleich zu skalieren). Mit einem Beispiel wird die klarer:
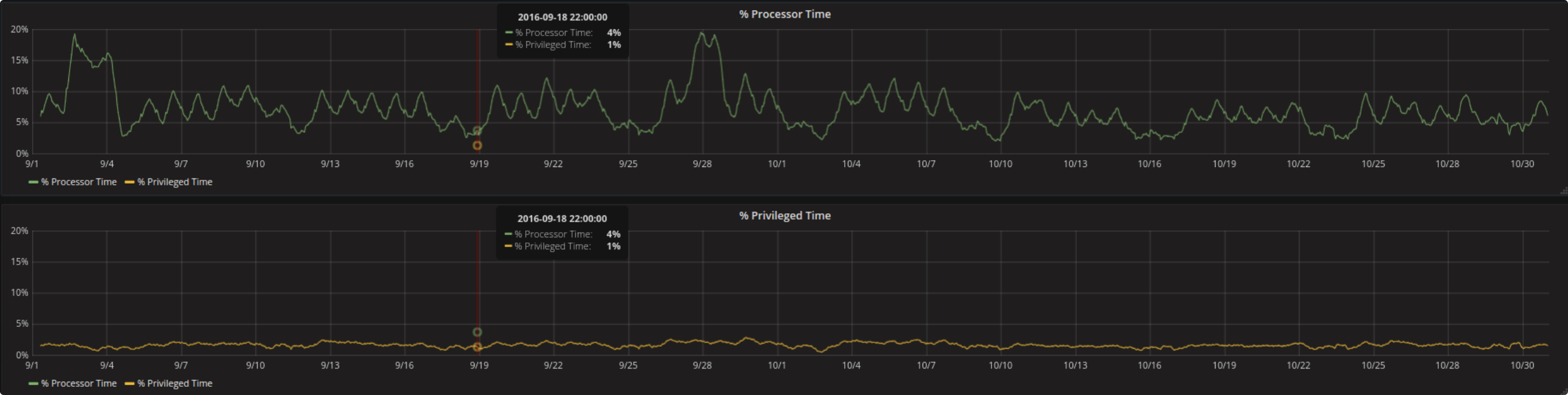
Die Prozessorzeit in Prozent und die Priviligierte Zeit in Prozent sind beide Metriken des gleichen Measurements (Prozessor). Um sie gleichzeitig in zwei separaten Graphen zu zeigen und die Y-Achse in beiden Graphen gleich zu haben werden die Werte der jeweiligen anderen Kurve versteckt dazu geladen (man muss die line width auf 0 setzen, lines = false wuerde dahingegen die Kurve ganz verschwinden lassen und somit die Skalierung ändern).
In so einem Setting (je nach Datenmenge) ist es möglich, dass der erste Graph (während er noch läd) den Ladevorgang des zweiten Graphs blockiert. Um so etwas zu erkennen und dementsprechend darauf zu reagieren können wir erneut den Einsatz der DevTools empfehlen.
STÜCKWEISES LADEN VON DASHBOARDS
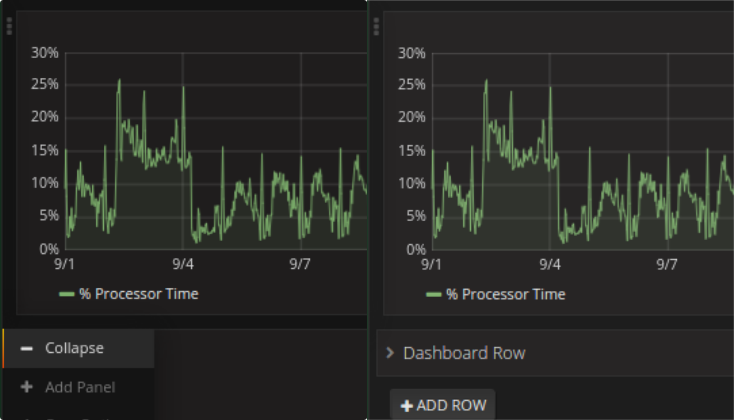
Sollte ein Dashboard mehr als einige wenige Panels enthalten, empfielt es sich zu überdenken, ob alle wirklich ab Beginn nötig sind, oder manche eigentlich nur gebraucht werden, wenn aus anderen bereits Information abgelesen wurde. Zusätzlich zur Organisation in Panels kann man das Dashboard auch in mehrere Reihen gliedern. Das hat den Vorteil, dass man Reihen ausblenden kann und die darin enthaltenen Panels nur geladen werden, wenn sie aufgeklappt werden.
ZUSAMMENFASSUNG
Bei der Erstellung von Dashboards sollte stets auch an Denjenigen gedacht werden, der sie eines Tages verwenden soll und insbesondere an die Auflösung der Kurve bzw. die Dichte an Datenpunkten, die dieser User tatsächlich braucht. Sollte es nicht möglich sein automatisches Grouping zu verwenden empfiehlt es sich eine Template Variable zu setzen, die den Group By Wert regelt. Beim ersten Laden auf einen größeren Wert gesetzt, beschleunigt sich der Ladevorgang erheblich und dem User ist dennoch die Möglichkeit gegeben, später eine andere Auflösung zu wählen (in der Hoffnung, dass dann längeres Laden nicht mehr so schlimm ist).
Transformationen und/oder Maths sind hilfreich um die Kurven so zurecht zu bekommen, dass der User es mit dem Ablesen für ihn relevanter Informationen erheblich leichter hat.
Chrome DevTools sind das A und O wenn es ums Debuggen von Grafana Dashboards geht.

Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix
13. 11. 2017
NetEye
Deep Learning – a Recent Trend and Its Potential