
02. 08. 2017
Susanne Greiner
Anomaly Detection, Machine Learning, NetEye, Real User Experience
Next Level Performance Monitoring – Part II: The Role of Machine Learning and Anomaly Detection
Machine learning and anomaly detection are being mentioned with increasing frequency in performance monitoring. But what are they and why is interest in them rising so quickly?
From Statistics to Machine Learning
There have been several attempts to explicitly differentiate between machine learning and statistics. It is not so easy to draw a line between them, though.
For instance, different experts have said:
- “There is no difference between Machine Learning and Statistics” (in terms of maths, books, teaching, and so on)
- “Machine Learning is completely different from Statistics.” (and the only future of both)
- “Statistics is the true and only one” (Machine Learning is a different name used for part of statistics by people who do not understand the real concepts of what they are doing)
The interested reader is also referred to:
Breiman – Statistical Modeling: The Two Cultures and Statistics vs. Machine Learning, fight!
In short we will not answer this question here. But for monitoring people it is still relevant that the machine learning and statistics communities currently focus on different directions and that it might be convenient to use methods from both fields. The statistics community focuses on inference (they want to infer the process by which data were generated) while the machine learning community puts emphasis on the prediction of what future data are expected to look like. Obviously the two interests are not independent. Knowledge about the generating model could be used for creating an even better predictor or anomaly detection algorithm.
Anomaly Detection and Standard Alerting
Once baselining seemed like THE solution for the definition of meaningful alerts. Today with network traffic being much more heterogeneous and with the explosion of the Internet of Things, additional strategies are needed. This is where anomaly detection comes into play. What exactly is an anomaly? It is a data point that for some reason is not standard. There are several types of anomalies:
- Point anomalies:
A single data point is different from the rest. An example could be a processor always oscillating between a certain range that has a sudden peak outside that range.
- Contextual anomalies: One or more data points can be declared as anomalies, when they are strange in a context-specific way. For example values that are typical at night might not be typical during the working day. The low values shown in the graph below (with the orange highlight) are thus not strange because they are low (in fact, there are lots of low values like that elsewhere in the graph) BUT because of the fact that they happen during the working day when the number is expected to be higher.
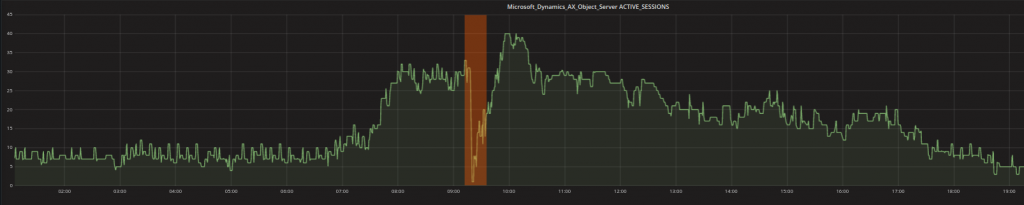

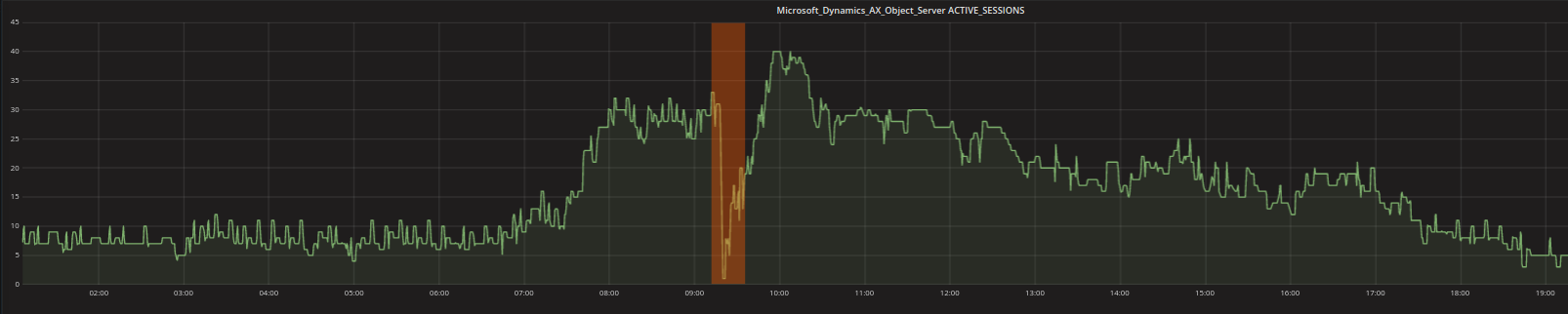
- Collective anomalies: Multiple values occurring together can also hint that there is an anomaly (more data points or metrics together, not individual metric values). The two most common types are events in an unexpected order and unexpected value combinations. For instance, a processor peak might be perfectly plausible as long as there are actual and requested transactions that the processor is currently working on. A processor peak together with other metrics that indicate the system ought to be idle however, should indicate something worthy of investigation.
What does this mean? In plain words it means, that there are some situations where standard methods are unable to trigger an alarm because those cases can only be detected by techniques that are more sophisticated than baselining. I am not saying that these more sophisticated techniques completely replace baselining but they do constitute a valid addition to standard techniques, especially when the consequences of not detecting these anomalies are significant.
Next Level Performance Monitoring
Let us now explore how anomaly detection can enrich the potential of Würth Phoenix’s Next Level Performance Monitoring solution. For instance, what would a human expert do when searching for reasons why the system is slow (or other issues)?
- Check whether there is actually a real problem
- Try to find where the problem comes from
- Further analyze the issue
- Solve the issue and consider potential actions for avoiding similar issues in the future
In practice this process might look like:
- Check with Alyvix and Anomaly Detection whether there is actually a real problem. Yes there might be, since in the figure below Alyvix is showing a test with notable delays as well as a period where no data was registered (black spaces between bars). Anomaly Detection (central graph of the figure) shows time points that can be considered riskier than standard activity at about the same time periods.
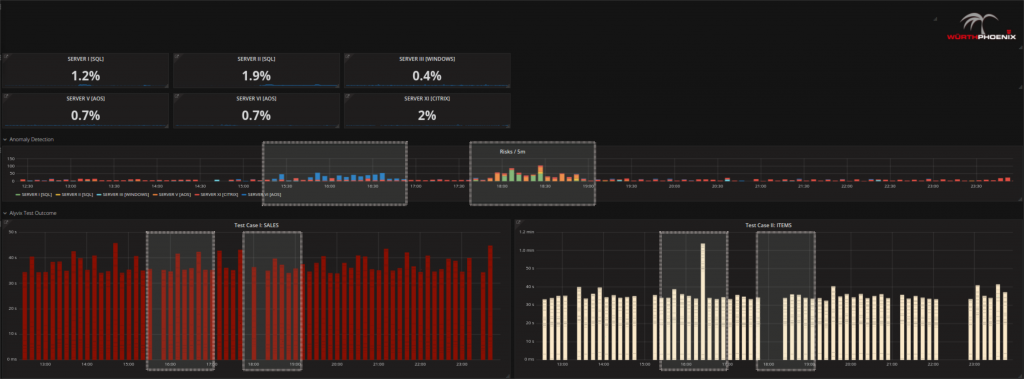
- Try to find out where the issue comes from:
If you already suspect a certain server given the problem, go straight to it by clicking on the server overview tabs at the top. Otherwise, scroll with your mouse over the RISKs detected by Anomaly Detection and continue to drill down on insights found there.
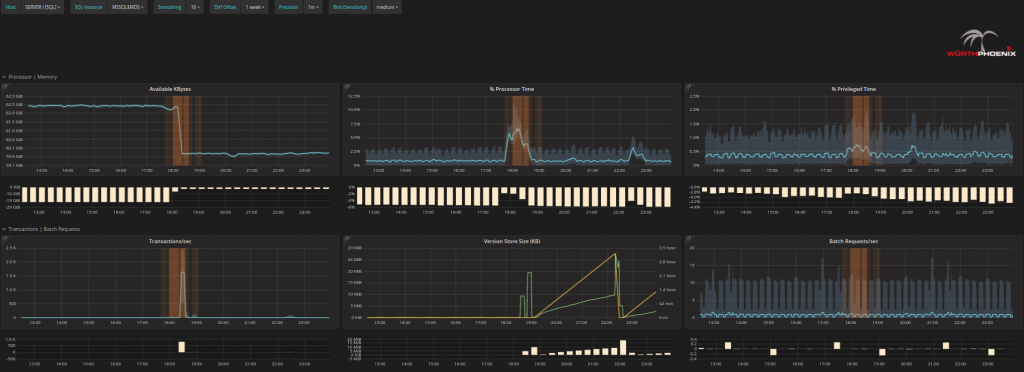
- Further analyze the issue:
You can analyze each issue as far down as operations on single disks and, single processors to see how their behavior changes for a detailed understanding of what is happening or might happen in the future.
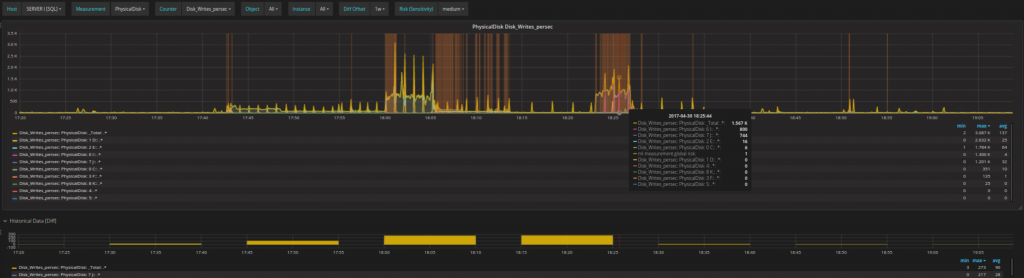
- Solve the issue and consider potential actions for avoiding similar issues in the future.
You can get immediate feedback whether your intervention corrected the issue or had some effect such as lower RISKs, lower DIFFs (difference with historical values), or similar.
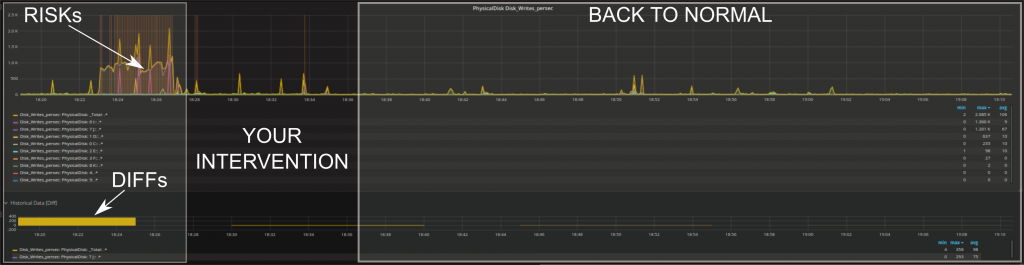
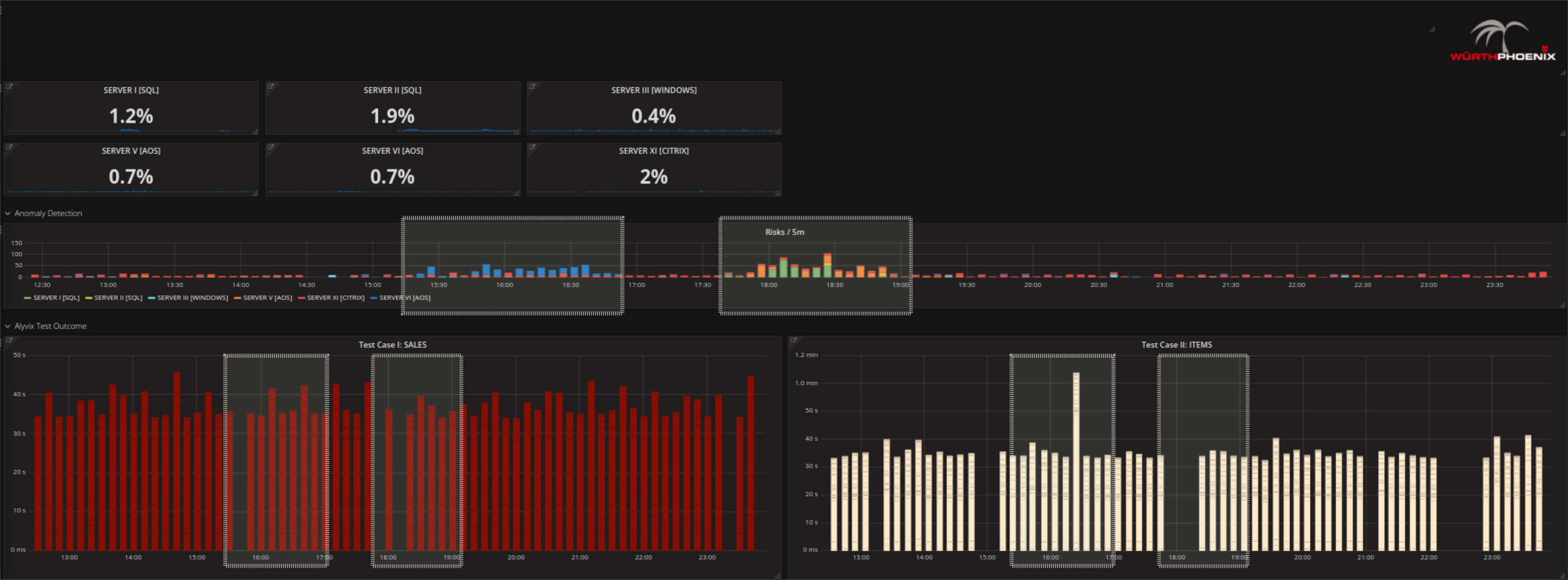
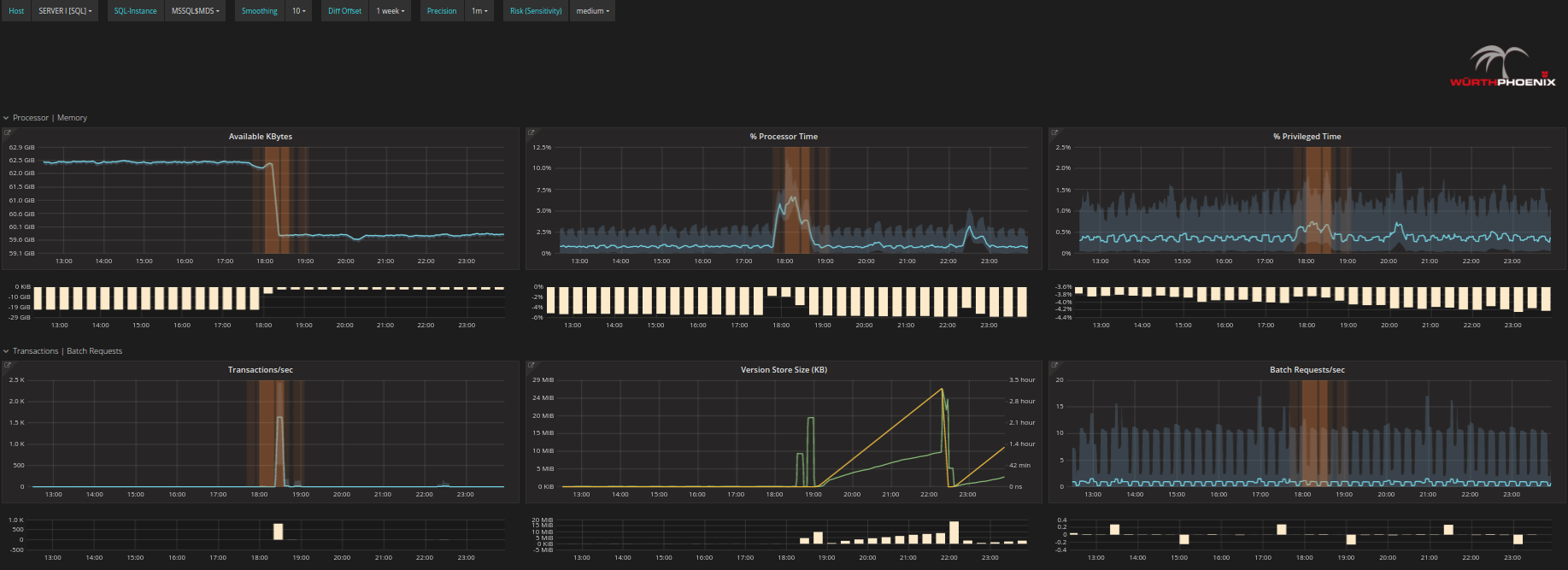

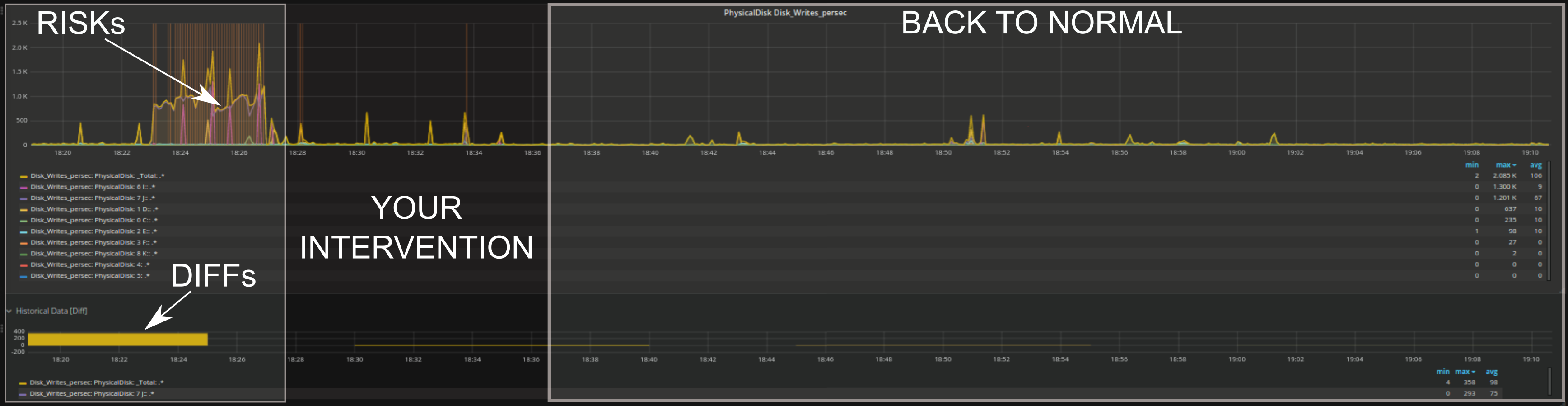
As you can see above, we have implemented anomaly detection in the form of RISKs. A RISK in this context is anything that deviates from standard behavior. Typical methods (e.g. baselining) have only a single way to determine that a given behavior is unusual; for instance, they may only detect events far outside the standard range of each individual metric. Anomaly detection, on the other hand, is able to identify multiple types of changes and is very dynamic over time.
The advantage of extending next level performance monitoring by the use of anomaly detection quickly becomes apparent. Risks can speed up the process of discovering which time periods are the most critical. Those that are out of the ordinary should be considered first when trouble shooting, because the probability of being related to the root cause of the problem is higher. Multivariate analysis makes it possible to analyze the behavior of many metrics together AND to study potential relations between them, while the human eye is not able to evaluate more than a few metrics at a time. Anomaly detection algorithms can be tuned further by adding more information about your system performance metrics over time, by dynamically learning from historical data, or by integrating domain knowledge whenever a human expert draws a conclusion from data. All in all you might say that we currently use anomaly detection within our solution as a first indicator of where to check first. The results can be expected to partially overlap with alerts created in the standard way, but it is also possible to detect different and potentially dangerous combinations before there is a real problem. Finally the output of anomaly detection can be combined with standard alerts for example to filter them into groups of events of more or less relatedness.







Susanne Greiner
Hi there! My name is Susanne and I joined Würth-Phoenix early in 2015. Ever since I can remember computers and the perfection that can be reached by them have been very fascinating for me. I built my first personal PC using components from about 20 broken ones at the age of 11 and fell in love with open source, visualization and data analysis shortly afterwards. I hold a master in experimental physics (University of Erlangen, Germany) and a PhD in computer science (Universtiy of Trento, Italy) my main interests are machine learning, visualization techniques, statistics and optimization. As long as an algorithm of mine runs at night and I get new interesting results the morning after I am able to sleep well. Beside computers I also like music, inline skating, and skiing.
Author
Latest posts by Susanne Greiner
21. 09. 2018
NetEye, Service Management
HackTheAlps Challenge with Würth Phoenix
04. 04. 2018
Anomaly Detection, Events, ITOA, NetEye
Würth Phoenix @ GrafanaConEu 2018
27. 03. 2018
Anomaly Detection, ITOA, NetEye, Visual Synthetic Monitoring
Multi-Level Dashboarding with Grafana – Use Case: NetEye ITOA | Alyvix