





10. 03. 2026
Unified Monitoring

02. 10. 2020
Enrico Alberti
Log-SIEM, NetEye
NetEye Ingest Pipelines – How to Modify and Enrich SIEM Data
Is it possible to add Geo IP information automatically to my events even if it’s not present in the original log? How can I automatically decode a URL to dissect all its components? How can I convert a human readable byte value (e.g., 1KB) to its value in bytes (e.g., 1024) so I can use it on a Kibana dashboard?
One answer that everyone knows is: Logstash Filters. But there’s another very smart option available from NetEye 4.9 that’s not used very often: the Ingest Pipeline. This feature offers the possibility to enrich or modify events automatically before they are indexed in Elasticsearch.
Concepts
- Ingest Node
Use an ingest node to pre-process documents before the actual document indexing takes place. The ingest node intercepts bulk and index requests, applies transformations, and then passes the documents back to the index or bulk APIs. All Elastic nodes enable ingest by default, so any node can handle ingest tasks. - Pipeline
A pipeline is series of processors that are to be executed in the same order as they are declared. A pipeline consists of two main fields: a description and a list of processors, as in the example below:
{
"description" : "...",
"processors" : [ ... ]
}The description is a special field to store a helpful message about what the pipeline does.
The processors parameter defines a list of processors to be executed in order.
How the Processor Works
An ingest pipeline changes documents before they are actually indexed. You can think of an ingest pipeline as an assembly line made up of a series of workers, called processors. Each processor makes specific changes, such as lowercasing field values, to incoming documents before moving on to the next one. When all the processors in a pipeline are done, the completed document is added to the target index.
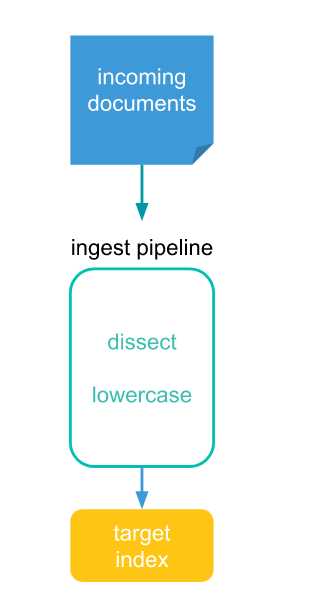
Pipeline Creation
Let’s go ahead and make our pipelines:
1. Add geoIP Information to All Incoming Events
The geoip processor adds information about the geographical location of IP addresses based on data from the Maxmind GeoLite2 City Database. Because the processor uses a geoIP database that’s installed on Elasticsearch, you don’t need to install your own geoIP database on machines running Logstash.
- Pipeline creation:
PUT _ingest/pipeline/geoip-info
{
"description": "Add geoip info",
"processors": [
{
"geoip": {
"field": "client.ip",
"target_field": "client.geo",
"ignore_missing": true
}
},
{
"geoip": {
"field": "source.ip",
"target_field": "source.geo",
"ignore_missing": true
}
},
{
"geoip": {
"field": "destination.ip",
"target_field": "destination.geo",
"ignore_missing": true
}
},
{
"geoip": {
"field": "server.ip",
"target_field": "server.geo",
"ignore_missing": true
}
},
{
"geoip": {
"field": "host.ip",
"target_field": "host.geo",
"ignore_missing": true
}
}
]
}
- Add the pipeline to the Logstash output:
...
elasticsearch {
hosts => ["elasticsearch.neteyelocal:9200"]
index => "my-index"
pipeline => "geoip-info"
codec => "plain"
...
Note: The Elastic GeoLite DB used automatically by the processor must be set up to have the geo point up to date, even if the Geo IP information is still the same. See the Max Mind Site.
2. Extract the User Agent from Web Server Events (Apache2)
The user_agent processor extracts details from the user agent string that a browser sends with its web requests. This processor adds that information by default under the user_agent field.
Sample : 10.10.3.110 - - [01/Oct/2020:15:27:51 +0200] "GET /neteye/layout/menu?url=%2Fneteye%2Fdoc%2Fmodule HTTP/1.1" 200 11665 "https://neteye4.wp.lan/neteye/doc/module/update/chapter/update-general-update" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0"
PUT _ingest/pipeline/user-agent-apache2
{
"description": "Extract details from the User Agent on Apache2 Logs",
"processors": [
{
"user_agent": {
"field": "user_agent.original",
"target_field": "user_agent",
"ignore_missing": true
}
}
]
}
Result on Elastic Index:
...
"user_agent": {
"name": "Firefox",
"original": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0",
"version": "81.0",
"os": {
"name": "Windows NT",
"version": "10.0",
"full": "Windows NT 10.0"
},
"device" : {
"name" : "Other"
},
...3. Convert Bytes from Human-readable Units to a Decimal Value
The bytes processor converts a human-readable byte value (e.g., 1KB) to its value in bytes (e.g., 1024). If the field is an array of strings, all members of the array will be converted.
PUT _ingest/pipeline/bytes-convert
{
"description": "Converts Bytes filed from human to its value in bytes.",
"processors": [
{
"bytes": {
"field": "file.size",
"target_field": "file.size",
"ignore_missing": true
}
}
]
}
Can We Apply Pipelines in Sequence?
The solution: use a main pipeline, with various nested pipelines to enrich all logs based on conditionals
- Create the main pipeline
- Add one or more conditions to delegate changes to other pipelines
PUT _ingest/pipeline/main-pipeline
{
"description": "Exec processor in sequence.",
"processors": [
{
"pipeline": {
"name": "geoip-info"
}
},
{
"pipeline": {
"if": "ctx.event?.module == 'apache'",
"name": "user-agent-apache2"
}
},
{
"pipeline": {
"name": "bytes-convert"
}
}
3. Add the main pipeline to Logstash
...
elasticsearch {
hosts => ["elasticsearch.neteyelocal:9200"]
index => "my-index"
pipeline => "main-pipeline"
codec => "plain"
...
The pipeline and processors are very powerful and versatile instruments that can help enrich logs ingested on NetEye SIEM more easily. And if you don’t find what you need in the out-of-the-box processors made by Elastic, you can even directly write a Painless script! (see script processor)
Useful links:
Elastic Ref: Ingest Processors
Other pipelines use: Firewall Log Collection

Enrico Alberti
I’ve always been fascinated by the IT world, especially by the security environment and its architectures.
The common thread in my working experience is the creation of helpful open-source solutions to easily manage the huge amount of security information.
In the past years, my work was especially focused on Cyber Kill Chain, parsing and ELK Stack but in order to start from the beginning...
In 2010 I left my birthplace, the lovely Veneto, looking for a new ´cyber´ adventure in Milan. After graduating in Computer Systems and Networks Security, I worked for 6 years as a Cyber Security Consultant.
During the first 5 years, I explored the deep and manifold world of cybersecurity, becoming passionate about open source solutions. After that, I decided to challenge myself joining a Start-up company focusing on SOC services (I’m a proud member of the Blue Team!).
In Wuerth IT Italy, I would like to personalize the NetEye System for each one of our customers, in order to develop the perfect product for their needs, by combining all my past experiences and skills.
Author
Latest posts by Enrico Alberti
28. 12. 2023
Log Management, Log-SIEM, NetEye
Monitor Fleet Elastic Agents with NetEye Extension Packs (NEP)
28. 10. 2022
Log Management, Log-SIEM, NetEye
Syslog Collection with Elastic under Distributed NetEye Monitoring
19. 07. 2022
Contribution, NetEye, Unified Monitoring
Integration of Centreon Plugins into NetEye Extension Packs