06. 05. 2024
Unified Monitoring

15. 06. 2022
Giovanni Davide Saccá
Unified Monitoring
Into the Flows: Collecting Data with nProbe and nTop
The role of these two components is pretty clear: nProbe has the role of collecting traffic data, while nTop makes that data visible and easily analyzable.
There is something, however, that needs to be explicitly stated, which is to decide whether it’s ntopng that should contact nProbe or vice versa, and as we’re in a segmented network environment, this is also something that needs to be contextualized:

ntopng -i tcp://< IP Address of nProbe>:5556
nprobe –zmq “tcp://*:5556 -i eth1 -n none -T “@NTOPNG@”
If it happens for example, that ntopng can reach nProbe, then the above configuration is perfect. But in cases where nTop cannot reach nProbe, whereas nProbe can reach nTop, then the configuration follows this second pattern:
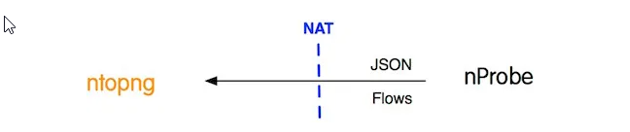
ntopng -i tcp://*:5556c
nprobe –zmq “tcp://<IP Address on ntopng>:5556 –zmq-probe-mode –collector port 6363 -n none -T”@NTOPNG@
The latter is typically the configuration I adopt for clients so that ntopng can collect flows from one or from multiple nProbes, and see the collector c on the ntopng CLI, even if nProbe is allocated on a separate network, behind a NAT, or shielded behind a firewall.
Basically I prepared for any segmented network environment that sees nProbe and ntopng in a distributed environment, with the following diagram describing the flow of network traffic:
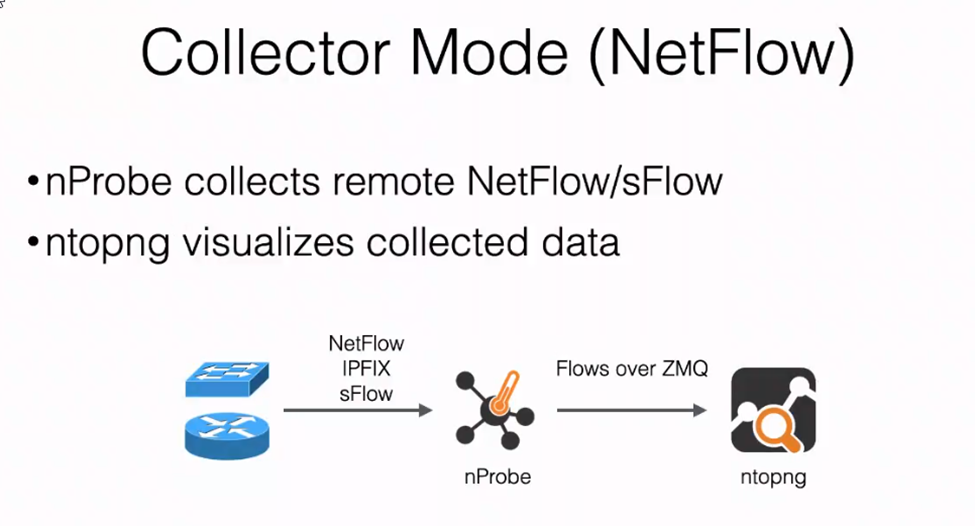
ntopng will keep the Active Flows and Hosts collected from the network traffic in the memory cache which has a preset cutoff. For more information, consult the ntopng WEB GUI at:
Menu Settings -> Preferences -> Cache Settings
If ntopng has difficulty handling the large number of Active Flows and Hosts, a red badge will be visible on the Traffic DashBoard in the upper right corner.
You can also indicate the maximum number of Hosts and Active Flows that ntopng is able to handle in the ntopng configuration file, with the respective directives -x for Hosts, and -X for Active Flows.
Consult the local ntopng help for further information:
[root@srvneteye4 ~]# ntopng --help
ntopng x86_64 v.5.0.211015 - (C) 1998-21 ntop.org
Usage:
ntopng <configuration file path>
or
ntopng <command line options>
Options:
[--max-num-flows|-X] | Max number of active flows | (default: 131072) [--max-num-hosts|-x] | Max number of active hosts | (default: 131072)
Usually I prefer to put each directive for ntopng in its own configuration file. This way whenever ntopng restarts it will restart with the same configuration.
Assuming we have 35K Active Host, then the -x value should be configured to at least 70K, and assuming 20K flows, then the -X value should be configured to 40K; in other words, set them to double the maximum size you expect on your network.
It’s better to have a larger value than a smaller one: small values mean that you will not be able to see all hosts, and performance will also be poor due to the poor tuning of ntopng. Larger values require ntopng to use more memory, however if you have plenty of RAM it’s not good to use extremely large values as you will waste resources for no reason.
Another parameter that needs to be configured in the ntopng configuration file is -m, which is useful for listing local networks. Make sure you set the actual networks you plan to use or that are inherent in your IP address plan, this will allow you to identify within the Active Flows the Local Hosts versus the Remote Hosts, like this:
[--local-networks|-m] | Local networks list.
| is a comma-separated list of networks
| in CIDR format. An optional '=' is supported
| to specify an alias.
| Examples:
| -m "192.168.1.0/24,172.16.0.0/16"
| -m "192.168.1.0/24=LAN_1,192.168.2.0/24=LAN_2,10.0.0.0/8"
It will be easier to identify the Top Talkers this way, where the accuracy you can manage can be somewhat controlled.
For example, if an ntopng instance manages many hosts, you might choose to reduce the precision for the benefit of the speed of generating the relevant reports; but if an ntopng instance manages just a few hosts, then raising the precision lets you to generate the relevant Reports quickly, as shown here:
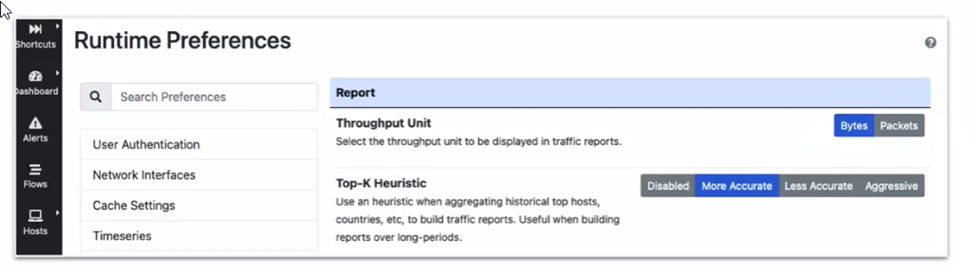
Finally, when choosing the backend for a NetEye 4 environment, we usually prefer data in RAM to storing the flows on InfluxDB. This guarantees performance even for a large number of time series, and it protects us in case the disk is slow.
You can easily configure the choice of backend directly from the ntopng WEB GUI:
Settings Menu -> Preferences -> Timeseries
as described in the blog post nProbe and nTop All-in-One (Single Node): Netflows Analysis.
These Solutions are Engineered by Humans
Did you read this article because you’re knowledgeable about networking? Do you have the skills necessary to manage networks? We’re currently hiring for roles like this as well as other roles here at Würth Phoenix.
Giovanni Davide Saccá
Hi all, my name is Davide and I was born in San Donato Milanese. Since I was a boy I've always been intrigued by PCs, and so I took my first steps with my Commodore VIC-20. Before joining Würth Phoenix as an SI consultant, I worked first as a Network Engineer for several ISPs (Internet Service Providers) in the late 90s, then for the first ASP (Application Service Provider) and next as a head of IT Network and Security. My various ITIL and Vendor certifications have allowed me to be able to cooperate at multiple project levels. I like tennis, music, motorcycles and going on nature walks with my family.
Author
Latest posts by Giovanni Davide Saccá
15. 02. 2023
Unified Monitoring
NetEye GeoMap Module
15. 02. 2023
Unified Monitoring
Ntopng and Behavior Analysis
15. 02. 2023
NetEye, Unified Monitoring
Grafana: InfluxDB Query to Extract More Than a Single Metric in a Single Panel